
PostgreSQL Autovacuum Internals and Benchmark
Vacuum, or more precisely autovacuum, is the most important automatic maintenance task in PostgreSQL. It is key for performance, but also for long-term database survival. If it runs too often, it can damage performance. If it does not run often enough, performance can suffer. With too few workers, it takes too long. With too many, it consumes resources. If the maintenance work memory is not enough, the load can multiply due to multiple index scans. If you disable it completely, it will rise from the dead and run without limits.
I guess you get it. It is critical to understand what autovacuum does and how it does it.
Autovacuum is triggered when certain row count thresholds are crossed. In the final part of this post we describe a benchmark we run to validate if modified rows is the right approach to trigger automatic vacuum execution or we should consider something different like page based thresholds. We will also measure the impact index in vacuum.
This blog post explains how autovacuum works, but some previous basic understanding of PostgreSQL internals is required.
Here are the terms you’ll need, feel free to skip if you already know them:
- MVCC (multi-version concurrency control): Rather than overwrite a row, PostgreSQL keeps multiple versions of it. This is used to provide consistent views to the different transactions running at the same time, which is why obsolete row versions pile up when there are long running transactions and/or tables are not vacuumed. MVCC is used by transactions to determine row visibility.
- Tuple: One on-disk version of a row. A row updated three times leaves behind three tuples.
- Dead tuple: A tuple that is not visible to any transaction. Reclaiming these is the vacuum’s main job.
- Heap: A table’s main structure, where the tuples live. Indexes are separate structures.
- Page (block): The 8 KB unit PostgreSQL reads and writes. A heap is an array of pages. If a page is dirty, it means it contains data that hasn’t been written to disk yet.
- TID: A tuple’s address: which page, which slot. Inside of the pages there is an array that points to the actual row position in the page, the slot is the position in that array. This way row space inside of the page can be reorganized without changing the TID. Index entries are TIDs pointing into the heap.
- Vacuum: The operation that removes dead tuples (and does a few things more).
- Autovacuum: Vacuum that PostgreSQL runs for you, in the background, on its own schedule.
- Visibility map (VM): A small per-table bitmap flagging which pages have all tuples visible or frozen (see freezing).
- Freezing: Stamping old tuples as permanently visible, so their transaction IDs are no longer relevant (see Transaction ID wraparound). Here permanent is a bit misleading, if the row is modified, the permanent tuple will become a dead tuple and will be removed by vacuum.
- Transaction ID (XID) wraparound: Each transaction is assigned an ID. This ID identifies which transactions modified which rows and is thus critical for visibility. The problem is that the transaction counter is finite and eventually wraps around. To avoid problems, older rows must be marked as permanently visible (frozen), this way their transaction id becomes irrelevant.
- Bloat: Space allocated by dead tuples, as dead tuples are not visible, it is wasted space. Vacuum works to reduce it, but can’t always reverse it.
- Shared buffers: PostgreSQL’s in-memory page cache. Nearly all reads and writes pass through it.
- WAL (write-ahead log): Every change is logged here before it touches a data page, so the database can recover after a crash.
- Checkpoint: The point at which modified (“dirty”) pages in shared buffers are written out to the data files.
Launcher & Worker Architecture
The autovacuum launcher is a background process that starts autovacuum workers. Its goal is to start one worker per database every autovacuum_naptime seconds (default: 1 min). With N databases, this means the launcher starts a new worker roughly every autovacuum_naptime / N seconds, round-robin across databases. But it is not the launcher that starts the workers. It requests the postmaster to fork an autovacuum worker for the chosen database.
Workers, once spawned, run independently until they finish all eligible tables in their assigned database and then exit. Up to autovacuum_max_workers (default 3) workers can run concurrently, and there is no restriction on how many of those may be in the same database. If a database has many tables that need vacuuming, it can run multiple concurrent vacuum workers. In this case, workers coordinate to avoid vacuuming the same table.
A database approximately has a worker assigned every “nap time seconds” or later. A worker is assigned even if there are no tables requiring vacuum.
Table Selection & Prioritization
This is the process inside a worker:
- Scans
pg_classto enumerate all tables in the database, then fetches per-relation statistics (dead tuple counts, etc.) from the cumulative statistics system (pgstat) for each one. - Compares each table’s dead-tuple count against the vacuum threshold (see the formula below).
- Also checks if the table needs an ANALYZE (separate threshold).
- Also checks for anti-wraparound: if
pg_class.relfrozenxidage exceedsautovacuum_freeze_max_age(default 200M transactions), or ifpg_class.relminmxidage exceedsautovacuum_multixact_freeze_max_age(default 400M), the table is vacuumed regardless of all thresholds and evenautovacuum_enabled = offon the table.
Prioritization
There is no table-level priority sorting in a database. A worker vacuums tables in the order they are collected from the pg_class scan. do_autovacuum() in src/backend/postmaster/autovacuum.c iterates the table_oids list directly. The worker claims each table sequentially by marking it as “mine” in shared memory (this triggers a brief lock to the memory structure so two workers don’t pick the same table at the same time), and calls table_recheck_autovac() to re-read catalog/pgstat and confirm the table still needs work (as it could have been already vacuumed by another worker). Anti-wraparound urgency is handled one level up, at database selection: the launcher’s do_start_worker() preferentially dispatches a worker to whichever database is closest to the wraparound limit. So there is no dead-tuple-count-based ordering of tables. Within a database, processing order is effectively catalog order.
How Vacuum Finds Pages to Process
Once a table is selected, the worker doesn’t blindly scan every page. It uses the visibility map (VM) to skip pages that do not need vacuuming.
The Visibility Map
Every table has an associated visibility map, a bitmap with two bits per heap page:
- All-visible bit: every tuple on the page is visible to all current and future transactions. During a normal (non-aggressive) vacuum, this page can generally be skipped. There are no dead tuples to reclaim. However, even all-visible pages may be visited in some cases, such as for eager freezing or readahead optimization (pages are read sequentially even if some of them are not needed).
- All-frozen bit: every tuple on the page is frozen, marked with the
HEAP_XMIN_FROZENinfomask bits (since PostgreSQL 9.4, the value ofxminis preserved for forensics rather than physically overwritten withFrozenTransactionIdalthough a lot of people still think the xmin is changed). The page can be skipped even during aggressive/anti-wraparound vacuum. An aggressive vacuum must visit all pages that are not all-frozen to freeze as many tuples as possible.
The VM makes vacuuming efficient because it reduces the number of pages to visit while searching for dead tuples. If a 10GB table has dead tuples on only 50 pages, vacuum reads the VM (around 320KB for a 10GB heap, 2 bits per 8KB page) and then focuses on those 50 pages rather than the full 10GB. We already mentioned that a normal vacuum can also visit some additional pages for eager freezing or readahead, but the VM still eliminates the vast majority of random I/O.
Visibility-map bits are cleared by backends running DML statements and usually set by autovacuum workers or manually triggered vacuum operations.
The VM is also used by index-only scans to determine whether visiting the heap page to validate tuple visibility is needed. If the page in the VM is marked as “all-visible,” then visibility checks are not required and we don’t need that extra access, improving performance significantly.
The Scan Process
The worker performs a sequential scan of the heap, but guided by the VM:
- Read the VM to identify pages that are NOT all-visible and may contain dead tuples.
- For each such page, read it into shared buffers (if not already there).
- Examine each tuple’s header (
t_xmin,t_xmax,t_infomask) to determine if the tuple is dead, meaning it was deleted or updated, and no running transaction can see it anymore. - Dead tuples are collected into an in-memory dead-TID store, since PG17 a
TidStore, a compact adaptive-radix-tree keyed by block number that replaced the old sortedItemPointerarray and its hard 1 GB cap. Its size is bounded byautovacuum_work_mem(default -1, which falls back tomaintenance_work_mem, default 64MB). For manualVACUUM,maintenance_work_memis used directly. - If the work memory fills up before the table is fully scanned, the worker pauses the heap scan, processes the accumulated dead tuples (index cleanup + heap cleanup), then resumes the heap scan from where it stopped. This means a single vacuum of a large, heavily updated table may involve multiple passes through the indexes.
Limiting Cache Impact with the Buffer Ring
The step 2 above says “read the heap page into shared buffers”), but if vacuum has to pull every page it scans into shared_buffers, vacuuming a large table would evict the pages that other queries depend on, trashing the cache during a maintenance task. PostgreSQL prevents this with a buffer access strategy, commonly called a ring buffer.
Rather than allocating pages all over the shared pool, vacuum uses a small ring of shared pool pages that it reuses circularly: when it needs a buffer for a new page, and the ring is full, it recycles the oldest buffer in the ring instead of claiming another from shared_buffers. If vacuum needs a page already in the shared pool, that page is not added to the ring. The ring size is set by vacuum_buffer_usage_limit, default 2 MB in PG18 (256 buffers of 8 KB), ranges from 128 kB to 16 GB, with a limit of 1/8 of shared_buffers (you can set it higher, but it will limited to that value). A value of 0 disables the ring entirely, letting vacuum use as much of shared_buffers as it needs. The same limit applies to ANALYZE and to autovacuum (which runs the same vacuum code). The VACUUM command accepts a per-statement BUFFER_USAGE_LIMIT option.
The ring has consequences: When the buffer being recycled is still dirty, vacuum must write it out before reusing the slot. As WAL is written before the page, we have to flush any outstanding WAL for that page first. So once vacuum dirties more pages than the ring can hold, it begins doing its own writes inline rather than leaving them all for the checkpointer or background writer. This may look as a trade-off as the ring caps vacuum’s cache footprint, but requires vacuum to perform some of its own write-back (and WAL flushing) as it runs. But if a page was read into the ring, probably that pages was not very active and will not be read again soon. Raising vacuum_buffer_usage_limit (or setting it to 0) relaxes the limit: a faster vacuum. But a faster vacuum that will evict more active pages and later will require more work by the checkpointer.
Determining Tuple Liveness
For each tuple on a non-all-visible page, vacuum checks:
t_xmin(inserting transaction identified): Check whether it committed. If the inserting transaction aborted, the tuple is dead immediately.t_xmax(deleting/updating transaction identifier): Check whether it committed and is older than the oldest running transaction (OldestXmin). If so, no active transaction can see this tuple version and the tuple is dead.- Vacuum, like the other backends, reads
pg_xact(the commit log / CLOG) to determine transaction commit status, and sets hint bits (HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED, etc.) on tuple headers so future accesses don’t need to re-checkpg_xact. Changing the hint bits marks the page as dirty, but does not save that change in the WAL, unless specified in the configuration (checksums enabled or wal_log_hints). The purpose of the hint bits is help future transactions know the outcome of the inserting/modifying transactions without checking the commit log.
OldestXmin is the oldest transaction ID that any running transaction might still need to see, also known sometimes as the xmin horizon. Tuples deleted or replaced by transactions newer than OldestXmin cannot be vacuumed because some active transactions might still need them. This is why long-running transactions limit the space that vacuum can reclaim.
What Happens to Heap Pages
Once dead tuples are identified on a page:
- Dead tuple line pointers are set to
LP_DEADduring the heap scan phase. Later, after index cleanup removes all dangling index references, vacuum performs a second heap pass that converts these toLP_UNUSED, making the slots available for reuse. (For tables with no indexes, vacuum can markLP_UNUSEDimmediately since there are no index pointers to worry about.) - The page is compacted. Live tuples are shuffled toward the high end of the page, and free space is consolidated in the middle (between the line pointer array and the tuple data area). This is called page pruning/defragmentation. It updates the page’s
pd_lower(end-of-line pointers) andpd_upper(start-of-tuple data) to reflect the new free space. - The page is marked dirty in shared buffers. It will be written back to disk by the background writer, at the next checkpoint or if the ring buffer is full and vacuum needs that space. This is the
vacuum_cost_page_dirtycost event (adds 20 to the cost global cost of running vacuum operations). - The VM is updated. If, after removing dead tuples, every remaining tuple on the page is visible to all transactions, the all-visible bit is set. During aggressive/anti-wraparound vacuum, if all tuples are also frozen, the all-frozen bit is set.
- The FSM (Free Space Map) tree is updated periodically (every
VACUUM_FSM_EVERY_PAGESpages or after heap/index cleanup pass, not after every individual page is added to the FSM) to advertise newly available space, so future DML operations can reuse it.
Heap Truncation
After processing all pages, vacuum checks whether the last pages of the heap file are entirely empty (all dead tuples were removed and there are no live tuples). If so, it truncates the file, physically shrinking it and returning disk space to the OS. This is the only situation where vacuum reduces the on-disk size of a table. The space reclaimed in the middle of the file is reused, not returned to the filesystem.
Truncation requires an AccessExclusiveLock lock during the truncation, which can cause a short stall on concurrent access. Table truncation can be disabled per-table or globally with vacuum_truncate = off.
Index Cleanup
Index cleanup is also required and is often an expensive part of vacuum. Indexes must be cleaned because they contain pointers (TIDs) to heap tuples. If the corresponding heap tuple is dead, the index entry becomes a dangling pointer and must be removed.
The Process
- After the heap scan (or after
maintenance_work_memfills), vacuum has its dead-TID store populated (block-ordered). - For each index on the table, vacuum calls the index access method’s
ambulkdeletefunction. For B-tree indexes, this invokesbtbulkdelete()thenbtvacuumscan(), which scans the entire index in physical order (every page except the metapage, including all leaf pages), checking every index entry’s TID against the dead-TID store. Matching entries are removed. (Seebtvacuumscan()insrc/backend/access/nbtree/nbtree.c, which processes each page withbtvacuumpage().) - Only after all indexes are cleaned does vacuum go back and clean the heap pages (mark
LP_UNUSED, compact). This is handled bylazy_vacuum_all_indexes()followed by the heap cleanup phase insrc/backend/access/heap/vacuumlazy.c.
The order of operations is important: index entries must be removed before their heap tuple slots are recycled, otherwise an index scan could follow a pointer to a slot that now holds a different, unrelated tuple, returning incorrect results.
Why Index Vacuum Is Expensive
The PostgreSQL documentation for the ambulkdelete interface states:
This is a “bulk delete” operation that is intended to be implemented by scanning the whole index and checking each entry to see if it should be deleted.
There is no partial index scan optimization. The design requires scanning the index completely. The dead TIDs are sorted by heap location, but index entries are ordered by key value, so there is no way to locate only the affected index pages without scanning all leaf pages.
Consequences:
- Each index is completely scanned for every vacuum cycle. For a table with 5 indexes and 100GB of index data, vacuum reads 500GB of index pages each full pass.
- If the space for dead-TID is too small and the heap scan must pause mid-way,
ambulkdeleteis called multiple times, once per batch of dead TIDs. The documentation states: “Because of limitedmaintenance_work_mem,ambulkdeletemight need to be called more than once when many tuples are to be deleted.” Each call performs a full index scan. With a 100GB table, 64MB of work memory, and 5 indexes, this can result in dozens of full index scans. (PG17’sTidStorepacks far more dead TIDs into the same memory, so this multi-pass case is much rarer than it was in previous versions.) - This is why increasing
autovacuum_work_mem(ormaintenance_work_mem) for vacuum-heavy workloads can be required. If the autovacuum operation is written into the log (log_autovacuum_min_duration), look forindex scans.
Index Cleanup Optimizations
- Bypass optimization (near-zero dead tuples): when 2% or fewer of the table’s pages contain
LP_DEADitems and the accumulated dead-TID storage stays under 32MB, vacuum enters bypass mode: it skips both index cleanup and the second heap-vacuuming pass, avoiding a full index scan as the benefit is reduced. This avoids the jump between “zero dead tuples is instant” and “one dead tuple requires multiple full index scans”. (SeeBYPASS_THRESHOLD_PAGESinvacuumlazy.c.) INDEX_CLEANUPparameter:AUTO(default) allows the bypass optimization;OFFforces vacuum to always skip index vacuuming (accepting index bloat);ONforces full index vacuuming every time. TheOFFsetting is useful for emergency situations where you need vacuum to advancerelfrozenxidquickly. (See VACUUM documentation.)- B-tree “page deletion”: when a B-tree leaf page becomes empty after vacuum removes all its entries, the page is marked as deleted and can be recycled. The file does not reduce its size, but the pages can be reused later.
- Simple B-tree tuple deletion: when a query visits a dead tuple via an index scan, it can mark that pointer as dead in the index itself. If, at a later time, more space is needed in that page, instead of performing a split, the index entries pointing to dead tuples can be removed to make room for the new entry.
- Bottom-up deletion (PG14+): B-tree indexes can proactively remove known-dead entries during page splits, reducing the work left for vacuum.
Concurrency: Vacuum vs. Active Backends
Vacuum runs concurrently with normal database operations. It does not lock the table exclusively (it takes a ShareUpdateExclusiveLock, which conflicts only with other vacuums, ALTER TABLE, and certain CREATE INDEX operations).
Page-Level Locking
When vacuum needs to read or modify a heap page it uses the common shared buffer access locks:
- For reading (AKA identifying dead tuples), vacuum acquires a shared buffer content lock on the shared buffer.
- For pruning and freezing (AKA removing dead tuples, setting vm flags), vacuum requires a buffer cleanup lock. This is an exclusive lock (no other backend can hold a lock on the buffer). In a non-aggressive vacuum, if the cleanup lock cannot be obtained immediately (another transaction has a shared lock for example), vacuum skips pruning/freezing on that page and moves on. An aggressive (anti-wraparound) vacuum will wait for the lock instead.
- These locks are held only for the duration of the in-memory page operation and should be very fast. They do not block concurrent
SELECTorDMLon other pages.
What Happens When a Backend Reads a Page Being Vacuumed
- If vacuum is currently modifying the page (holding the cleanup lock): the backend waits until vacuum releases the lock, then reads the page in its post-vacuum state. The backend sees only live tuples. The dead ones have just been removed. This is safe because the dead tuples were invisible to the backend’s snapshot anyway.
- If vacuum skipped the page (could not get the cleanup lock): dead tuples remain on the page. They are invisible to backends via MVCC visibility checks and will be cleaned up in a future vacuum cycle.
- If vacuum has not yet reached the page: the backend reads normally. Dead tuples are still present but invisible to the backend’s MVCC snapshot. They are skipped during visibility checks.
What Happens When a Backend Writes While Vacuum Runs
- INSERT into a vacuumed page: vacuum freed space, the FSM knows about it, the inserter uses that space. No conflict.
- UPDATE/DELETE on the same table: concurrent DML does not conflict with vacuum’s
ShareUpdateExclusiveLock. If a backend deletes/updates a tuple on a page vacuum hasn’t reached yet, vacuum will find and clean it (if committed by then). If the tuple is on a page vacuum already passed, it will be caught by the next vacuum cycle. - UPDATE/DELETE on a page vacuum is currently processing: the buffer lock serializes access. If vacuum removes dead tuples and the backend then updates a live tuple on the same page, there’s no conflict because they operate on different tuple slots.
Index Scan During Index Cleanup
While vacuum scans an index to remove dead entries, concurrent index scans by backends can proceed normally. B-tree indexes use a pin-based protocol that avoids vacuum deleting a page that any backend has pinned. Specifically, vacuum marks pages as half-dead first, and only recycles them when no backend holds a pin. This ensures index scans never follow a pointer to a recycled page.
Threshold Formula
A table becomes eligible for autovacuum when its dead-tuple count crosses a threshold. As of PG18 the calculation is limited by autovacuum_vacuum_max_threshold:
vacuum_threshold = Min(
autovacuum_vacuum_max_threshold,
autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * reltuples
)Defaults:
autovacuum_vacuum_threshold = 50autovacuum_vacuum_scale_factor = 0.2autovacuum_vacuum_max_threshold = 100,000,000(new in PG18).
autovacuum_vacuum_max_threshold is used to avoid massive tables requiring a huge number of dead tuples before firing vacuum.
Insert-triggered vacuum (PG13+)
A table also becomes eligible based on inserts alone. Since PG18 the scale-factor term is multiplied by the unfrozen fraction of the table:
vacuum_insert_threshold =
autovacuum_vacuum_insert_threshold
+ autovacuum_vacuum_insert_scale_factor * reltuples * (1 - relallfrozen / relpages)Defaults:
autovacuum_vacuum_insert_threshold = 1000autovacuum_vacuum_insert_scale_factor = 0.2
The (1 - relallfrozen / relpages) is used to avoid time between runs constantly growing for tables that are mostly inserted. In previous versions, as the table grows the number of inserted rows required to trigger a vacuum used to grow also. With this optimization, the number of inserts required to trigger vacuum tends to be more constant.
ANALYZE trigger
The following formula applies to determine if ANALYZE is required:
changed_tuples > analyze_threshold + analyze_scale_factor * reltuplesDefaults: autovacuum_analyze_threshold = 50, autovacuum_analyze_scale_factor = 0.1.
Per-table overrides via ALTER TABLE ... SET (autovacuum_vacuum_scale_factor = ...) that take precedence over default configuration.
Cost-Based Vacuum Throttling
The cost-based mechanism is linked directly to the page-level operations described above. Every time vacuum touches a page, it incurs a cost depending on what happened:
Vacuum I/O is throttled via a cost/delay mechanism shared with manual VACUUM:
vacuum_cost_page_hit= 1, page already in shared buffers (cheap: no I/O, only CPU to inspect tuples)vacuum_cost_page_miss= 10 (PG17 and earlier; changed to 2 in PG18), page read from OS into shared buffers (may still be in OS page cache, so not necessarily a physical disk read)vacuum_cost_page_dirty= 20, vacuum modified the page (removed dead tuples, compacted it). This is the most expensive because it generates a dirty buffer that must eventually be written to disk by the background writer/checkpointer
These costs are additive per page. On PG17 (miss = 10): a page read from disk and then modified costs 30. On PG18 (miss = 2): the same scenario costs 22. A page already in shared buffers (hit = 1) that gets modified costs 21 on both versions.
The cost limit is shared across all running autovacuum workers. If 3 workers are active, each effectively gets 200 / 3 or around 66 cost budget per cycle. This means adding more workers doesn’t linearly increase I/O as all workers get their cost limit reduced. The global limit is autovacuum_vacuum_cost_limit, that by default is -1, meaning it inherits vacuum_cost_limit, which by default is 200.
The workers accumulate cost points as operations happen. When, for a specific worker, the accumulated total reaches its assigned limit, the worker will sleeps for autovacuum_vacuum_cost_delay (default 2ms).
Example
With defaults (limit=200, delay=2ms), one worker on PG17 (miss=10):
- If all pages are a miss + dirty write (cost 30 each): 200/30 ~ 6 pages, then sleep 2ms, giving ~3,000 pages/sec.
- If every page is already in shared buffers and gets modified (hit + dirty = 21): 200/21 ~ 9 pages, then sleep 2ms, giving ~4,500 pages/sec.
- If all pages are a shared-buffer hit with no modifications (cost 1 each): 200 pages, then sleep 2ms, giving ~100,000 pages/sec.
On PG18 (miss=2), miss + dirty reduces the cost to 22 per page, so throughput for cold pages rises to 200/22 ~ 9 pages per cycle.
If we have 3 workers sharing the limit, then each gets 66 cost/cycle, so throughput per worker drops proportionally.
For large this default is often too conservative. Common tuning: raise autovacuum_vacuum_cost_limit to 1000-2000 and/or reduce cost_delay to 0 on critical tables.
The manual VACUUM parameter vacuum_cost_delay defaults to 0 (no throttling). Autovacuum workers use autovacuum_vacuum_cost_delay, which has the default value of 2ms since PG12 (earlier versions defaulted to 20ms). Per-table storage parameters autovacuum_vacuum_cost_delay / autovacuum_vacuum_cost_limit override the globals for that specific table. This a way to tune the impact of high-churn tables on the shared cost.
What Drives Vacuum Cost
As we’ve seen, autovacuum is triggered by the number of dead or inserted tuples. But is the real cost driven by the number of dead tuples, or by the number of pages it has to visit and clean?.
We designed a benchmark to try to discover which is the real cost driver for autovacuum operations.
The question
We have two hypotheses that we want to analyze:
- Whether autovacuum cost is driven by the count of dead tuples or by the number of heap pages those dead tuples are spread across.
- How the number of indexes amplifies that cost.
The table and the key variable
We will use a single table for every run of the benchmark. We will drop and recreate the table each time:
CREATE TABLE bench_table (
id INTEGER NOT NULL, -- sequential 1 .. 10,000,000
val INTEGER NOT NULL DEFAULT 0,
padding TEXT NOT NULL -- repeat('x', 96)
);The padding column fixes the row width at 128 bytes, giving around 58 rows per 8 KB page. For 10M rows we will have 172,414 heap pages or 1.3 GB. We fill the table, then run VACUUM FREEZE so every page starts all-visible and all-frozen to have a clean baseline. Then we create 0 to 5 redundant B-tree indexes, all on id. Each index is a separate physical structure that vacuum must scan in full.
The independent variable here is the distribution of dead tuples. We use two strategies delete the same number of rows. They differ only in which pages are touched:
| Strategy | DELETE predicate (10%) | Pages dirtied |
|---|---|---|
| compact | WHERE id <= 1,000,000 | first ~10% of pages (low ids = first physical pages) |
| spread | WHERE id % 10 = 0 | 100% of pages (every page loses between 5 and 6 rows of its 58 rows) |
For this benchmark, we use DELETE rather than UPDATE so no new tuple versions are created. The table does not grow and no index entries are added (no leaf page splits).
The test matrix
We have 6 index counts (0-5), multiplied by 3 dead-tuple percentages (10/25/50%) and 2 distributions gives us 36 combinations. We repeated each combination 10 times for a total of 360 runs.
How a single run is measured
- Recreate the table, fill it with data,
VACUUM FREEZE, build the required indexes for the test (autovacuum disabled on the table throughout setup). DELETEto generate the dead tuples for this combination.- Pre-test
CHECKPOINT: flush the buffers dirtied during setup, so the post-test checkpoint will only account for pages autovacuum makes dirty. - Reset the shared I/O counters:
pg_stat_reset_shared('io' | 'bgwriter' | 'checkpointer'). Note that we do not callpg_stat_reset(), which would zeron_dead_tupand prevent autovacuum from triggering. - Record the start time, then enable autovacuum on the table with parameters that should trigger autovacuum (
autovacuum_vacuum_threshold = 1,autovacuum_vacuum_scale_factor = 0). Asautovacuum_naptimeis 1s, the launcher should pick the table up approximately within a second. - Poll every 0.5 s until vacuum is done:
last_autovacuumis after start_timeandn_dead_tup = 0`. - Stop the clock, force a post-test checkpoint, and collect metrics.
What is captured, and from where
| Signal | Source | Notes |
|---|---|---|
Wall-clock duration_s | clock_gettime (monotonic) | approximate time (vacuum+nap) |
| Autovacuum-worker reads/hits/writes | pg_stat_io, filtered to backend_type = 'autovacuum worker' | isolates the worker from every other process (PG18) |
| Heap vs index blocks | pg_statio_user_tables (before/after diff) | specific table data |
| Write breakdown | pg_stat_io per backend + pg_stat_checkpointer | who wrote the dirty pages |
| Dirty-page count / completion | pg_visibility_map_summary (from pg_visibility) |
I/O is recorded two ways: operation counts (reads/writes, which can be multi-block) and byte-derived page counts (read_bytes/write_bytes ÷ 8192, exact regardless of multi-block coalescing). We decided to look at the byte-derived counts. Each combination’s 10 iterations are aggregated as a median with an interquartile (Q1-Q3) band.
Results
This is the test environment we used:
- PostgreSQL: 18.4 (PGDG,
pg_visibilitycontrib) - OS / host: Ubuntu 24.04 LTS, x86_64, 4 dedicated vCPU / 15 GiB RAM, SSD-backed
- Execution: benchmark runs locally on the DB host over the Unix socket (no network in the timing path)
- Key GUCs:
shared_buffers = 4GBmaintenance_work_mem = 1GBwork_mem = 64MBautovacuum_naptime = 1sautovacuum_vacuum_cost_delay = 2msautovacuum_vacuum_cost_limit = 200vacuum_cost_page_miss = 2checkpoint_timeout = 15minmax_wal_size = 4GBfull_page_writes = ontrack_io_timing = on
- Per-table triggers:
autovacuum_vacuum_threshold = 1autovacuum_vacuum_scale_factor = 0
- Workload:
- Table with 10,000,000 rows (172,414 heap pages, ~1.3 GB)
- 2.4 GB working set with 5 indexes (around 225 MB each), fits completely in
shared_buffers
- Sampling: 36 combinations x 10 iterations = 360 runs
The whole 2.4 GB working set (heap plus five 225 MB indexes) is resident in shared_buffers. The maintenance_work_mem = 1 GB keeps index cleanup single-pass. Autovacuum throttling is at the default (cost_delay = 2ms). Durations below are 10-iteration medians.
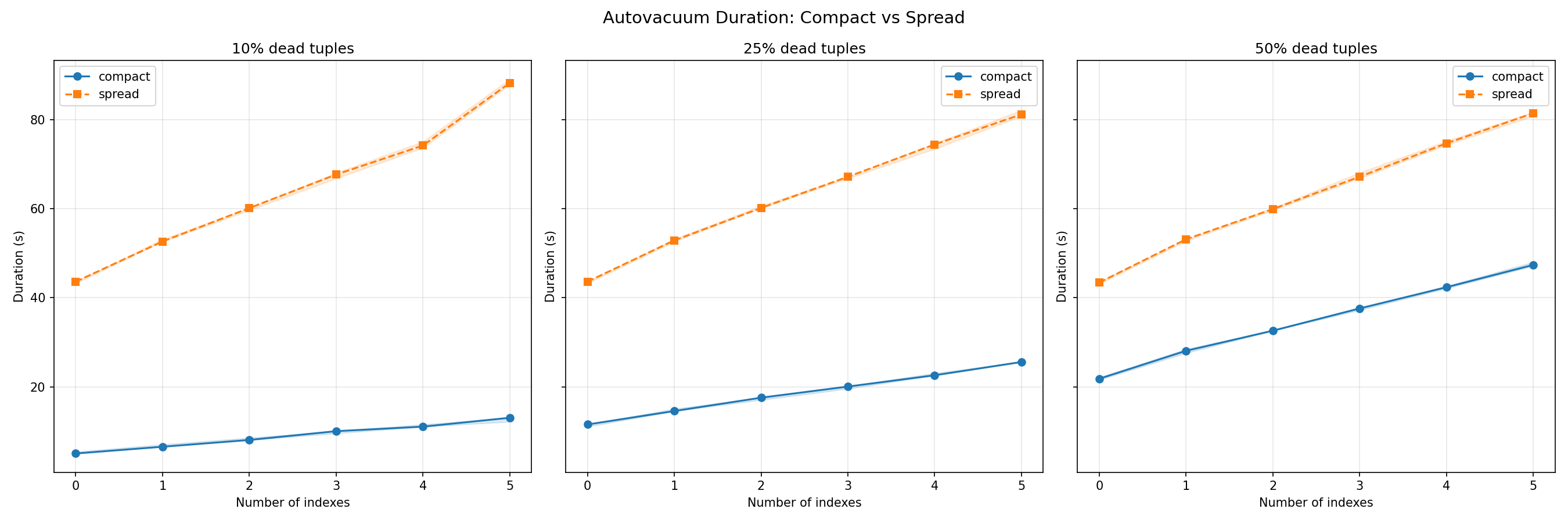
Hypothesis 1: it’s pages, not tuples. At 0 indexes:
| dead tuples | compact | spread | spread / compact |
|---|---|---|---|
| 10% (1.0M) | 5.0 s | 43.6 s | 8.7x |
| 25% (2.5M) | 11.5 s | 43.6 s | 3.8x |
| 50% (5.0M) | 21.8 s | 43.4 s | 2.0x |
First thing we see is that the spread column is almost constant (43.6, 43.6, 43.4 s) as the dead-tuple count goes from 1M to 5M, because in every case 100% of pages are dirtied. This means that pages visited is the cost driver. Meanwhile the compact column scales because, for compact, more dead tuples means more pages become dirty. When we have 50% dead tuples, the cost is half the spread.
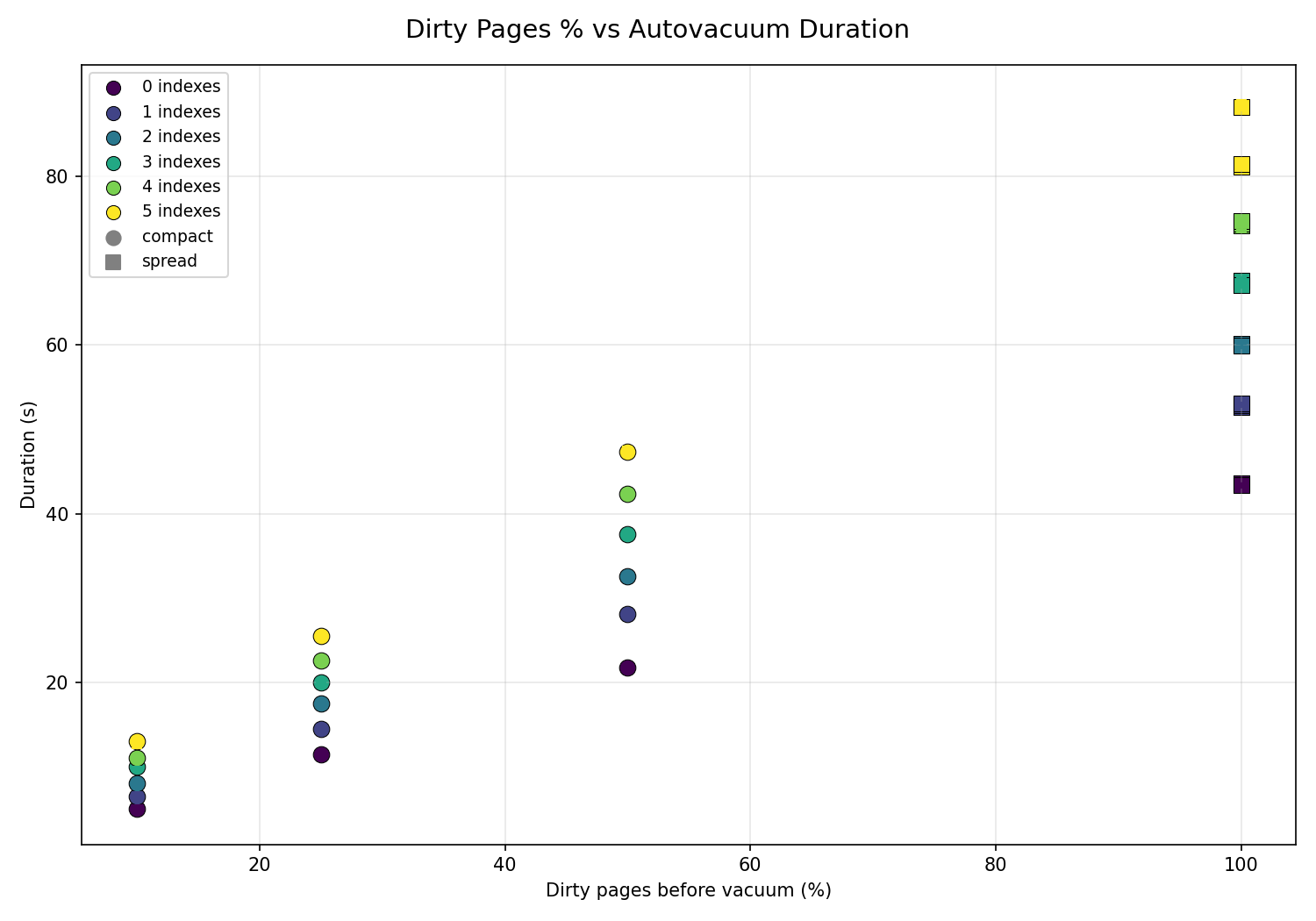
The following chart plots every run by dirty-page percentage rather than dead-tuple count.
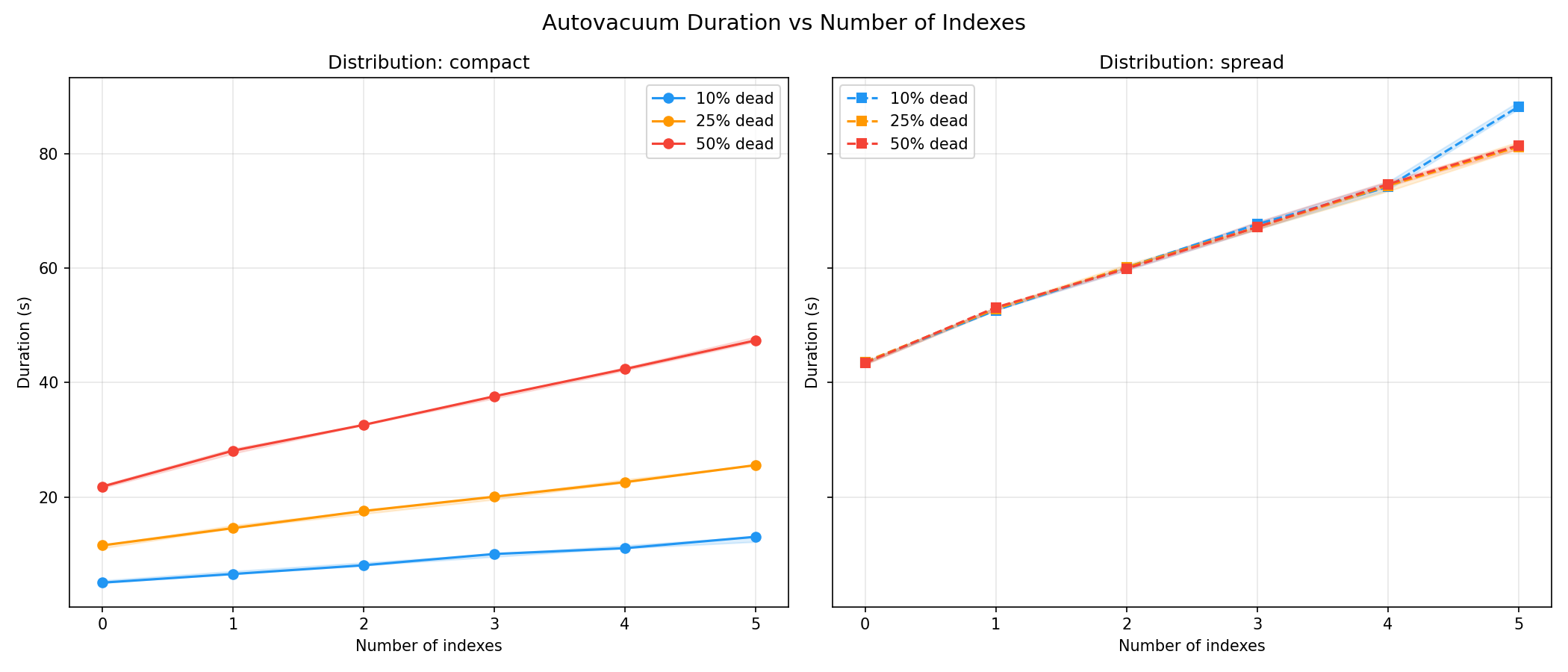
For the second hypothesis, we see that indexes amplify the cost. Each redundant index adds a near-constant increment (compact 50%): 21.8, 28.1, 32.6, 37.6, 42.3, 47.4 s. Around 5s per index. The number of dead pages also adds some cost, but if the number of dead pages is reduced, then the impact of indexes is lower (compact 10%)
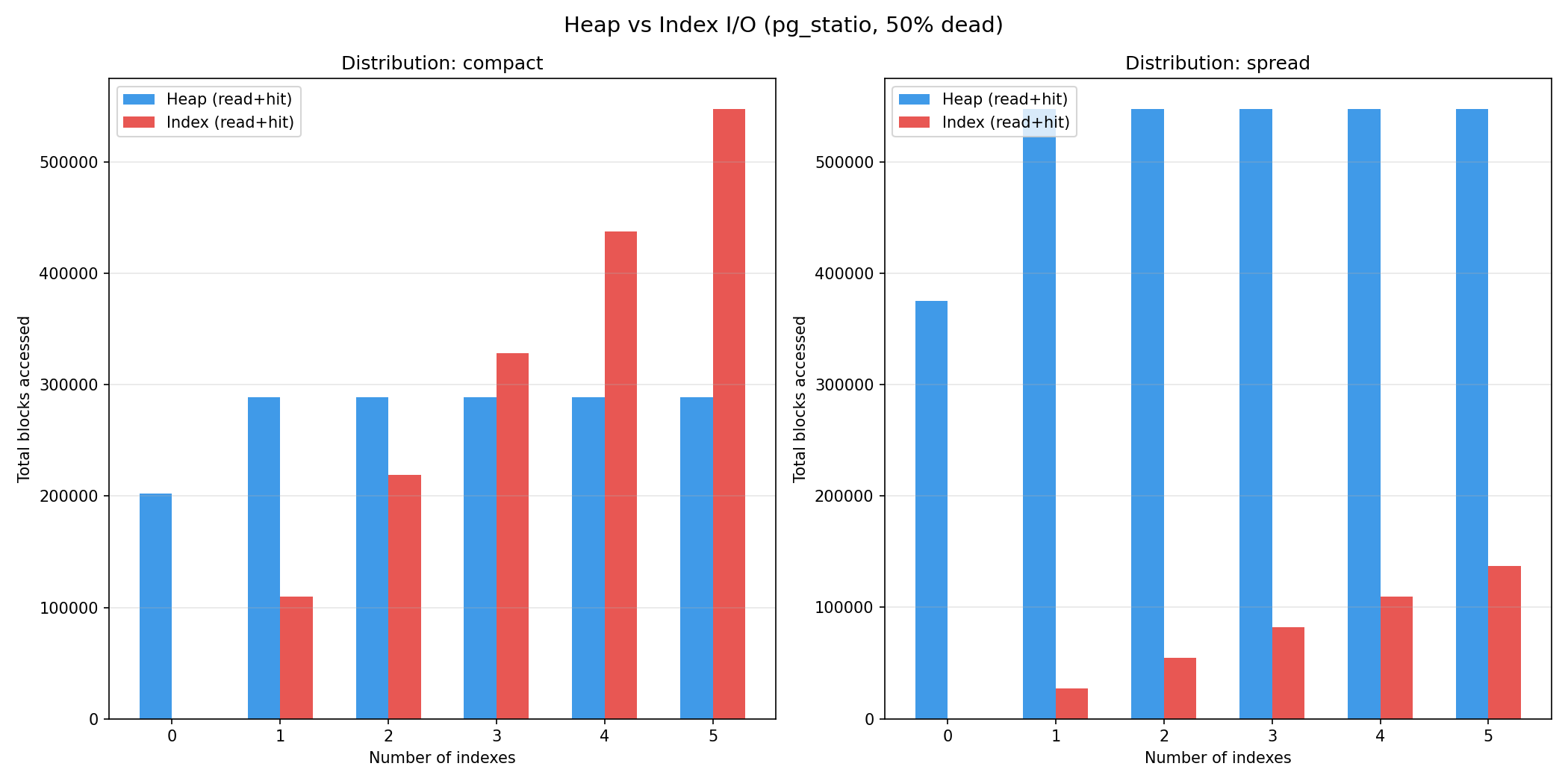
The I/O data shows some distribution-specific behaviors. For spread 50%, heap blocks accessed hold at 547,323 across 1-5 indexes (the heap is scanned once, guided by the VM) while index blocks grow +27,422 per index. Each ambulkdelete is a full leaf scan. Compact 50% behaves differently: the heap io is lower (288,699, since fewer pages have dead tuples) but index blocks climb 4x faster (~+109,533 per index). Deleting contiguous id ranges empties whole B-tree leaf pages, adding page-deletion and recycling work (B-trees recycle fully-empty pages rather than merging partially-filled ones) on top of the scan. One thing worth noting is that heap access is not flat from 0 to 1 index, it jumps (spread 374,903 to 547,323) because index cleanup forces vacuum’s second heap pass. After that, it is flat only across 1-5 indexes.
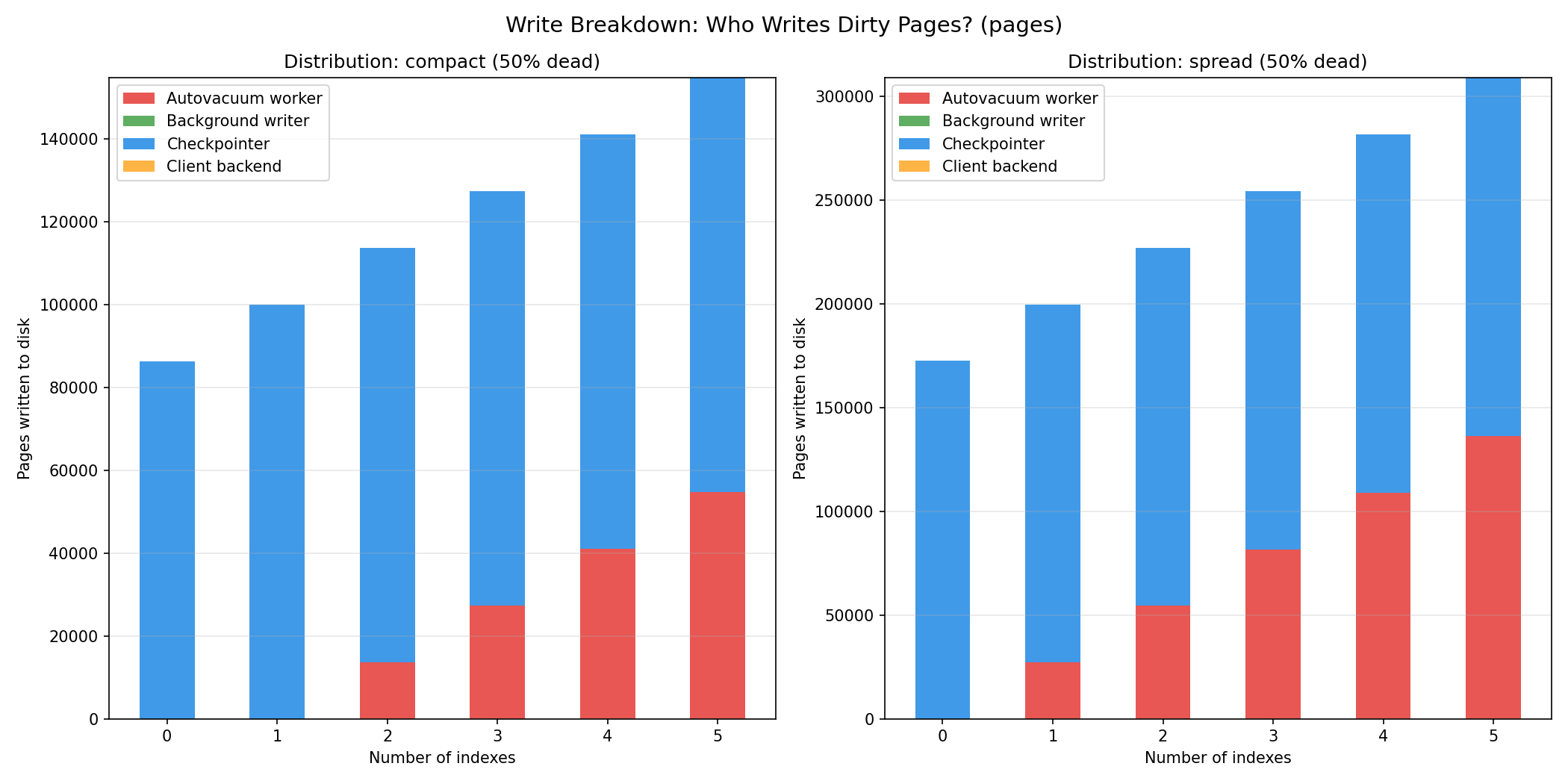
The write breakdown tells us that who writes vacuum’s dirtied pages is not fixed. With zero or one index, the autovacuum worker writes almost nothing: it dirties heap buffers and leaves them for the checkpointer, which flushes all of them in those cases. But as indexes are added, the worker’s own writes increase: spread 50% goes 0, 27k, 54k, 82k, 109k, 136k pages written by the worker for 0-5 indexes (compact 50%: 0, 0, 14k, 27k, 41k, 55k). This is the effect of the buffer ring (see Limiting Cache Impact above): once index cleanup dirties more pages than the 2 MB ring can hold, the worker has to write and evict them itself rather than defer to the checkpointer. So the write cost shifts from the checkpointer toward the worker as index count grows, a direct consequence of the cache-protecting ring.
Finally we have a heat map of the durations across all 36 combinations:
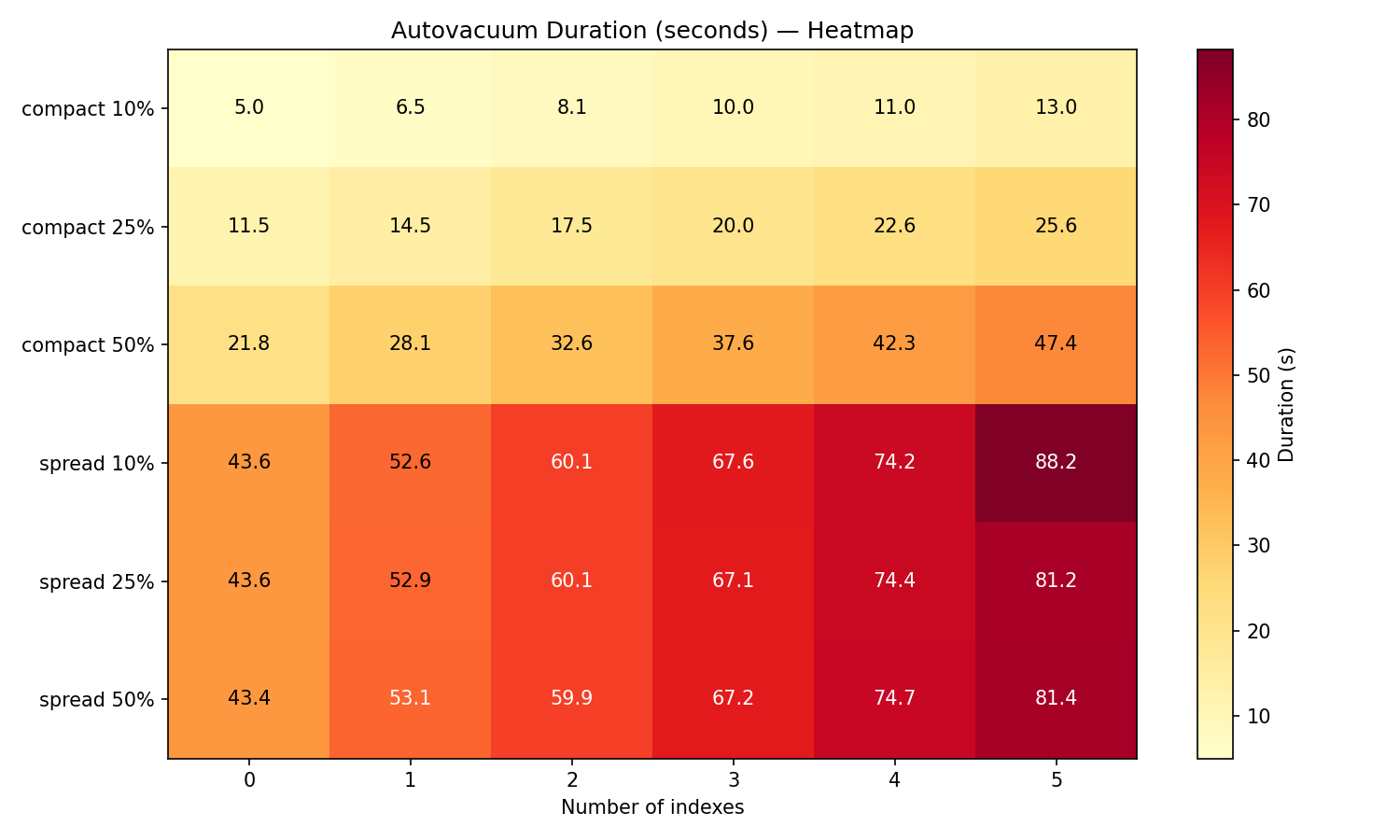
So our conclusion is, as expected, that dirty pages is the main cost driver for autovacuum, followed by the number of indexes. And that we may have the same number of dead rows with completely different autovacuum costs.
What this benchmark does and does not show
The result is clear, but getting a clear result using a synthetic workload should be read with care. Our benchmark intentionally avoids complexity. And complexity is what makes production vacuum hard.
- We built a
VACUUMbenchmark wearing autovacuum’s clothes. With one table,threshold = 1,scale_factor = 0, andnaptime = 1s, we measure the isolated work of a single worker on one table. It says nothing about the parts that are specific of autovacuum: launcher table-selection,autovacuum_max_workerscontention, or the cost limit shared across workers. The scheduling dynamics are often critical, and they are absent here. - The workload we use in the benchmark, as usual for a benchmark, is synthetic. Dead tuples come from a single bulk
DELETEon an idle table. There is no concurrency. There are no long-running transaction holding backOldestXmin. Real vacuum routinely skips pages it can’t get a cleanup lock on (see Concurrency). In our case, this never happens, which is why every run cleans to 100% all-visible. The benchmark measures vacuum on an idealized table, not production churn. - Everything fits in memory, so this is not an I/O-bound situation. With the whole table in
shared_buffers, reads are mostly buffer hits, and writes are largely deferred to the checkpointer (the worker itself writes little except index pages at higher index counts). The “cost” being measured is page visits and CPU, plus deferred checkpoint writes. The vacuums that are I/O-bound due to scans of heaps and indexes that don’t fit in cache, are painful. This case is excluded from the benchmark and we may say that the conclusions are about logical work, rather than IO bound operations. We consider that IO bound operations could show greater differences, but we did not test them. - Redundant identical indexes don’t generalize. Five B-tree indexes on the integer column is a trick used to make index work scale linearly. Real indexes differ in width, key type, correlation, bloat, fill factor, and bottom-up-deletion behavior. The measured slope (5 s per index; 27,422 index blocks per index for spread, but 109,533 for compact) is specific to this shape (even the slope is distribution-dependent) and can not be directly extrapolated to wide, composite, or text indexes.
- Freezing was excluded. The
VACUUM FREEZEbaseline ignored freezing. Anti-wraparound / aggressive vacuums, which must visit every not-all-frozen page and are often the most disruptive events in production, are not part of this benchmark. Besides, the bypass optimization and multi-passambulkdelete(undermaintenance_work_mempressure) is avoided, and this makes vacuum runtime nonlinear and hard to predict in production.
Our findings are valid: vacuum cost is driven by dirty pages, not by dead-tuple count, and the mechanism behind it is clear. But the benchmark used a single table that fits entirely in memory, recently frozen, and ran with no concurrent activity. Under those conditions, both runtime and the page-visit counts grew linearly with the number of dirty pages and the number of indexes. It is not clear if these results can be extrapolated to a busy, larger-than-RAM production system. This is left for a future exercise.
References
PostgreSQL Documentation
- Index Access Method Functions. Defines the
ambulkdeleteandamvacuumcleanupinterfaces; documents that bulk delete is “intended to be implemented by scanning the whole index” - VACUUM SQL Command.
INDEX_CLEANUPparameter (AUTO/ON/OFF) andPARALLELoption for index vacuum - B-Tree Implementation. B-tree structure, deduplication, and bottom-up deletion (page-deletion and recycling mechanics are detailed in the
nbtree/READMElisted under Source Code below)
PostgreSQL Source Code
src/backend/access/nbtree/nbtree.c. B-tree vacuum implementation:btbulkdelete()thenbtvacuumscan()(physical-order scan of all index pages except the metapage),btvacuumpage()(per-page processing)src/backend/access/heap/vacuumlazy.c. Main VACUUM implementation: heap scan, dead tuple collection,lazy_vacuum_all_indexes()(iterates all indexes callingambulkdelete), bypass optimization (BYPASS_THRESHOLD_PAGES = 0.02)src/include/access/nbtree.h. B-tree data structures and constantssrc/backend/access/nbtree/README. Design notes on B-tree page deletion, recycling, and the half-dead/pin-based deletion protocol




Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.