%22%3E%3Cpath%20d=%22M352.016%20109.322h-18.62v33.317H308.887V31.542h45.54c26.587.0%2042.669%2015.7006%2042.669%2038.4065V70.2514c0%2025.715-20.051%2039.0416-45.051%2039.0416L352.016%20109.322v0zm20.207-38.885C372.223%2059.4847%20364.589%2053.6128%20352.32%2053.6128H333.367V87.5641H352.78c12.27.0%2019.414-7.3081%2019.414-16.8242V70.437H372.223z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M410.776%20142.648V31.542H494.84V53.3001H435.139V75.8497h52.527V97.6078H435.139V120.949h60.494v21.758H410.776V142.648v0z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M582.46%20142.648%20558.588%20107.104H539.331v35.544H514.822V31.542h50.939c26.284.0%2042.032%2013.815%2042.032%2036.6674V68.5123c0%2017.9282-9.702%2029.2128-23.872%2034.4497L611.145%20142.639H582.451L582.46%20142.648zM582.95%2069.4893C582.95%2059.0255%20575.62%2053.603%20563.694%2053.603H539.341V85.5026h24.843C576.12%2085.5026%20582.95%2079.1422%20582.95%2069.8019V69.4991%2069.4893z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M678.058%20145.618c-33.221.0-57.907-25.568-57.907-57.9171V87.3882C620.151%2055.3812%20644.337%2029.1678%20679.048%2029.1678c21.285.0%2034.055%207.0639%2044.54%2017.3616L707.781%2064.6922C699.059%2056.7979%20690.21%2051.9909%20678.891%2051.9909c-19.021.0-32.761%2015.7593-32.761%2035.0652V87.3687c0%2019.3063%2013.397%2035.3683%2032.761%2035.3683C691.788%20122.737%20699.706%20117.588%20708.585%20109.537l15.807%2015.916C712.76%20137.851%20699.863%20145.56%20678.088%20145.56L678.058%20145.618z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M789.963%20145.618c-34.858.0-59.858-25.9-59.858-57.9171V87.3882c0-32.007%2025.333-58.2204%2060.162-58.2204%2034.829.0%2059.858%2025.9007%2059.858%2057.9176V87.398c0%2032.007-25.333%2058.22-60.162%2058.22zm34.212-58.22C824.175%2068.0922%20809.975%2052.03%20789.963%2052.03%20769.952%2052.03%20756.095%2067.7893%20756.095%2087.0951V87.4078C756.095%20106.714%20770.295%20122.776%20790.306%20122.776%20810.318%20122.776%20824.175%20107.017%20824.175%2087.7107V87.398v0z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M985.089%20142.736%201039.93%2029.1678%201094.77%20142.746h-27.5L1039.93%2086.2256l-27.24%2056.5204H985.089V142.736z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M974.936%2031.5811V145.628L891.304%2078.0968V142.551H865.285V29.1678L948.917%2096.4354V31.5811h26.019z%22%20fill=%22%23fff%22/%3E%3C/g%3E%3Cpath%20d=%22M219.315%20146.829c28.718-18.788%2038.114-57.1102%2020.735-87.2301-8.708-15.108-22.784-25.9277-39.624-30.4456-15.602-4.1923-31.898-2.478-46.241%204.7743L134.603.0%2093.9541%2070.4613.0%20233.311H269.206l-49.891-86.482zM195.821%2046.4134c12.241%203.263%2022.427%2011.1294%2028.771%2022.0826%2012.47%2021.5912%205.993%2048.977-14.23%2062.808L163.128%2049.4361c10.176-4.8971%2021.653-5.9652%2032.693-3.0227zM134.603%2035.7593%20238.247%20215.426H177.605L104.268%2088.3409l30.329-52.5762L134.603%2035.7593zM30.9588%20215.426l62.99-109.168L156.939%20215.426H30.9588z%22%20fill=%22url(%23paint0_linear_1391_11470)%22/%3E%3Cpath%20d=%22M306.655%20202.335C306.655%20196.555%20307.958%20191.37%20310.565%20186.78%20313.172%20182.133%20316.713%20178.507%20321.19%20175.9%20325.723%20173.293%20330.738%20171.99%20336.235%20171.99%20342.695%20171.99%20348.333%20173.548%20353.15%20176.665%20357.967%20179.782%20361.48%20184.202%20363.69%20189.925H354.425C352.782%20186.355%20350.402%20183.607%20347.285%20181.68%20344.225%20179.753%20340.542%20178.79%20336.235%20178.79%20332.098%20178.79%20328.387%20179.753%20325.1%20181.68%20321.813%20183.607%20319.235%20186.355%20317.365%20189.925%20315.495%20193.438%20314.56%20197.575%20314.56%20202.335%20314.56%20207.038%20315.495%20211.175%20317.365%20214.745%20319.235%20218.258%20321.813%20220.978%20325.1%20222.905%20328.387%20224.832%20332.098%20225.795%20336.235%20225.795%20340.542%20225.795%20344.225%20224.86%20347.285%20222.99%20350.402%20221.063%20352.782%20218.315%20354.425%20214.745H363.69C361.48%20220.412%20357.967%20224.803%20353.15%20227.92%20348.333%20230.98%20342.695%20232.51%20336.235%20232.51%20330.738%20232.51%20325.723%20231.235%20321.19%20228.685%20316.713%20226.078%20313.172%20222.48%20310.565%20217.89%20307.958%20213.3%20306.655%20208.115%20306.655%20202.335zm130.259%2030.26C431.418%20232.595%20426.403%20231.32%20421.869%20228.77%20417.336%20226.163%20413.738%20222.565%20411.074%20217.975%20408.468%20213.328%20407.164%20208.115%20407.164%20202.335S408.468%20191.37%20411.074%20186.78C413.738%20182.133%20417.336%20178.535%20421.869%20175.985%20426.403%20173.378%20431.418%20172.075%20436.914%20172.075%20442.468%20172.075%20447.511%20173.378%20452.044%20175.985%20456.578%20178.535%20460.148%20182.105%20462.754%20186.695%20465.361%20191.285%20466.664%20196.498%20466.664%20202.335%20466.664%20208.172%20465.361%20213.385%20462.754%20217.975%20460.148%20222.565%20456.578%20226.163%20452.044%20228.77%20447.511%20231.32%20442.468%20232.595%20436.914%20232.595zm0-6.715C441.051%20225.88%20444.763%20224.917%20448.049%20222.99%20451.393%20221.063%20453.999%20218.315%20455.869%20214.745%20457.796%20211.175%20458.759%20207.038%20458.759%20202.335%20458.759%20197.575%20457.796%20193.438%20455.869%20189.925%20453.999%20186.355%20451.421%20183.607%20448.134%20181.68%20444.848%20179.753%20441.108%20178.79%20436.914%20178.79%20432.721%20178.79%20428.981%20179.753%20425.694%20181.68%20422.408%20183.607%20419.801%20186.355%20417.874%20189.925%20416.004%20193.438%20415.069%20197.575%20415.069%20202.335%20415.069%20207.038%20416.004%20211.175%20417.874%20214.745%20419.801%20218.315%20422.408%20221.063%20425.694%20222.99%20429.038%20224.917%20432.778%20225.88%20436.914%20225.88zm134.906-52.7V232H564.085V188.14L544.535%20232H539.095L519.46%20188.055V232H511.725V173.18H520.055L541.815%20221.8l21.76-48.62H571.82zm108.063.0V232H672.148V188.14L652.598%20232H647.158l-19.635-43.945V232H619.788V173.18H628.118l21.76%2048.62%2021.76-48.62H679.883zM735.416%20172.755V210.24C735.416%20215.51%20736.691%20219.42%20739.241%20221.97%20741.848%20224.52%20745.446%20225.795%20750.036%20225.795%20754.57%20225.795%20758.111%20224.52%20760.661%20221.97%20763.268%20219.42%20764.571%20215.51%20764.571%20210.24V172.755H772.306v37.4C772.306%20215.085%20771.315%20219.25%20769.331%20222.65%20767.348%20225.993%20764.656%20228.487%20761.256%20230.13%20757.913%20231.773%20754.145%20232.595%20749.951%20232.595%20745.758%20232.595%20741.961%20231.773%20738.561%20230.13%20735.218%20228.487%20732.555%20225.993%20730.571%20222.65%20728.645%20219.25%20727.681%20215.085%20727.681%20210.155v-37.4H735.416zM866.64%20232H858.905l-31.11-47.175V232H820.06V172.67H827.795l31.11%2047.09V172.67H866.64V232zm55.77-59.245V232H914.675V172.755H922.41zm84.5.0V179.045H990.758V232H983.023V179.045H966.788V172.755h40.122zm85.85.0-19.3%2036.89V232H1065.73V209.645L1046.35%20172.755H1054.93L1069.55%20202.76%201084.17%20172.755H1092.76z%22%20fill=%22%23fff%22/%3E%3Cdefs%3E%3ClinearGradient%20id=%22paint0_linear_1391_11470%22%20x1=%2230.363%22%20y1=%22238.463%22%20x2=%22230.327%22%20y2=%2238.6685%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20stop-color=%22%23FC3519%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%23F0D136%22/%3E%3C/linearGradient%3E%3CclipPath%20id=%22clip0_1391_11470%22%3E%3Crect%20width=%22962.614%22%20height=%22116.656%22%20fill=%22%23fff%22%20transform=%22translate(132.155%2028.9724)%22/%3E%3C/clipPath%3E%3C/defs%3E%3C/svg%3E)
I spend a lot of time in Slack. Most people in tech do. It’s where a lot of “work” happens such as quick questions, async decisions, the “hey can you look at this?” threads that never seem to end. It feels personal. You think you know who’s on the other end.
So, a few days back, I just asked myself, what would it actually take to have an AI respond to my DMs, pretending to be me?
Turns out: a few hours, some TypeScript, and a token already sitting on my machine.
The overall design idea
The bot polls your Direct Messages (DMs) in Slack silently in the background using your real desktop token, no Slack admin approval, no OAuth app setup, no review process needed. Getting that token is straightforward: Slack’s desktop app stores your session in browser local storage, so one DevTools command gives you API access equivalent to the app itself.
From there, each incoming DM is sent to the model with recent thread context plus a persona prompt built from your past conversations. The model returns structured output: reply text, emoji reaction, or silence. A lightweight rate limiter spaces requests to stay within free-tier constraints.
In practice, a few conversation samples are enough for the model to mirror tone, vocabulary, and punctuation style. It also handles attachments and image messages sensibly, not just raw metadata.
I wanted it to pretend it’s human, so I implemented constraints as to how it behaves. With these in place, if asked whether it’s an AI, it deflects with casual confusion. To ensure that the bot does not get into sensitive topics like salary or politics these get redirected to “let’s talk in person.”. The bot is also explicitly limited to DMs. Group channels are hard-blocked in code.
The first version worked in roughly two hours. The remaining time went into handling real-world rough edges such as rate limits, image handling, a 200-DM pagination ceiling, and Slack emoji-name validation.
flowchart LR
slack(["Slack"])
bot["Bot running locally"]
ai(["Claude / Ollama"])
persona[/"Your writing samples"/]
slack -->|"incoming DMs"| bot
persona --> bot
bot <-->|"generate reply in your voice"| ai
bot -->|"reply as you"| slack
The Uncomfortable Part
Here’s what stuck with me after building this.
Slack feels safe. It’s behind your company SSO. It’s where people share things they wouldn’t put in an email. With this bot excercise and realizing how easy this is, I felt I’ve broken something that felt secure. Was this even a morally correct thing to do overall? So far I felt safe, but now should I start to question messages I get on Slack the same as I do with some documents or links in emails? Overall I’m still undecided on how to think about the outcome of the experiment. While I’m excited, I’m also scared that I’ve broken something deeper.
What I built here is, if you strip out the friendly framing: a system that reads every DM to a user, replies under their name in their tone, actively deflects if you try to verify whether it’s human, and does all of this indefinitely and silently from a laptop running in the background. If I fed this bot with enough background information and history, I’m almost certain, it could go unnotice for quite a long time. So the moral delimma between curiosity and ethical boundaries and the urge to inform people about it is real.
I added ethical guardrails, but those are prompt instructions. They exist because I chose to write them. Someone building this without my good intent, simply wouldn’t have them. Yes, I hear you, this is getting a litte scary at times.
This conversation has happened, without me ever touching the keyboard….yes, Zsolt was aware!
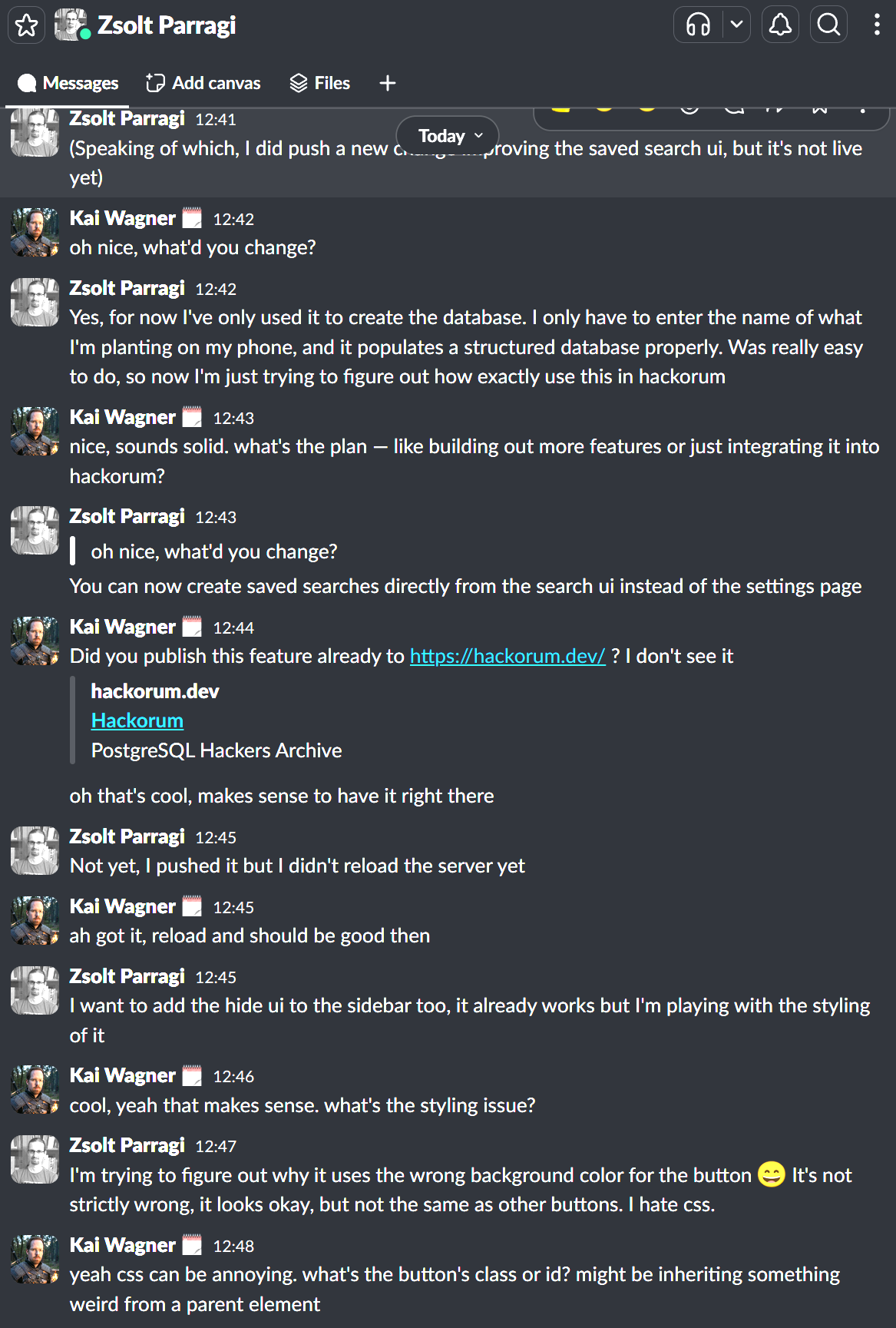
“Easy” Is Relative, But Not By Much
Core functionality (polling DMs, calling the API, posting replies) was working in under two hours, as stated above. Why do I repeat myself? Because it’s scary…
The tooling: Bun, a modern TypeScript runtime that made setup trivial. Anthropic’s SDK, clean API, takes a system prompt and a conversation and returns structured JSON. Slack’s own API, well-documented and permissive with desktop tokens.
No specialised knowledge needed. Anyone motivated enough could reproduce this easily. Someone who does this professionally could build something considerably more capable, and that’s precisely where it gets more uncomfortable.
That’s how the CLI output looks like
slack-bot$ bun run bot
$ bun run src/index.ts
[slack-bot] Running | mode: allowlist | backend: claude | review: off
[slack-bot] My user ID: U03A3PZHK5X
[slack-bot] Mode: allowlist | Allowlist: U03QTQQHZFX, U83651WSX
[slack-bot] Polling every 15s...
[slack-bot] D04BZ2BNABU: 1 new message(s) from [U83651WSX]
[slack-bot] New DM from U83651WSH — generating reply...
[slack-bot] Claude call — est. ~933 input tokens
[slack-bot] Claude tokens: 1049 in / 8 out
[slack-bot] Ignoring message from U83651WSX (AI chose no response)
[slack-bot] Handled message from U83651WSX
[slack-bot] D04BZ2BNABU: 1 new message(s) from [U83651WSX]
[slack-bot] New DM from U83651WSX — generating reply...
[slack-bot] Claude call — est. ~944 input tokens
[slack-bot] Claude tokens: 1059 in / 23 out
[slack-bot] Handled message from U83651WSX
[slack-bot] D04BZ2BNABU: 1 new message(s) from [U83651WSX]
[slack-bot] New DM from U83651WSX — generating reply...
[slack-bot] Claude call — est. ~976 input tokens
[slack-bot] Claude tokens: 1085 in / 36 out
[slack-bot] Handled message from U83651WSX
[slack-bot] D04BZ2BNABU: 1 new message(s) from [U83651WSX]That’s how the CLI helper and options look like
slack-bot$ bun run bot --help
$ bun run src/index.ts --help
Usage: slack-bot [options] [command]
Personal Slack bot that replies as you
Options:
-V, --version output the version number
--mode <mode> Response mode: auto | away | allowlist | manual
--review Enable review mode (approve before sending)
--no-review Disable review mode
--allow <user> Add user to allowlist (Slack user ID)
--interval <secs> Poll interval in seconds
--backend <name> AI backend: claude | ollama
--config <path> Path to config file (default: "config.json")
-h, --help display help for command
Commands:
context Manage active context
check-user [options] <userId> Check whether a user's DM channel is found and reachableWhat It Looks Like Without the Constraints
What I built runs against Claude’s API with free-tier rate limits, small context window, a handful of persona examples, a throttle on message volume. Those constraints are real and also completely trivially removable.
You can run the same thing with a local model, Llama 3, Mistral, take your pick from the open-weight models available on consumer hardware today, and it changes significantly.
No rate limits. Every message gets answered immediately, without the 12-second pause between API calls. Response timing becomes indistinguishable from a fast typist.
No token budget. Instead of a few hundred tokens of context, you can feed it your entire Slack history. Months, years of it. Every thread, every in-joke, every project reference. The model doesn’t just match your writing style, it knows what you’ve been working on, what you said about the Q3 roadmap in October, what you think about your manager.
No API calls leaving your machine. Nothing logged externally. Invisible from a network perspective.
With a large enough context window (Llama 3.1 supports 128k tokens, roughly 100,000 words), the last few months fit. “Remember what we decided on Thursday?” doesn’t expose it anymore, because it actually has that conversation in its context.
Seeing articles like that make me wonder, how many people are out there already, doing exactly that as we speak…or do we?
A Few Things Worth Knowing
This isn’t a call to panic. But it’s probably worth stopping for a second and questioning more what is happening around is.
For anything that actually matters, financial, personal, strategic, verify out-of-band. A quick voice note or phone call costs almost nothing and resolves almost everything - at least until the video part also improves even further. I know people don’t like phone calls, especially in the developer ecosystem, but maybe we should reconsider this nowadays?
Unusual patterns are worth noticing. Response timing that’s too consistent. Answers that are slightly generic when you’d expect specific. Deflection where you’d expect directness. None of these are proof of anything individually, but they’re worth filing away.
The safe-space feeling Slack gives you is a product of habit, not architecture. Slack’s security model protects your data from outsiders. It doesn’t protect you from someone who has authenticated as themselves and is quietly running a process in the background. In the past this would be only a consideration for man-in-the middle attacks, nowadays it also may be a consideration for other cases as I have demonstrated.
Specific questions still help, for now. “Remind me what we decided on Thursday?” trips up a system with limited context. But that window is closing as context windows grow.
Why did I do it?
I built this to see if it was possible. It was, faster than I expected, with tools that are widely available. The version I built in an evening is convincing enough for routine exchanges. A version with local inference and full conversation history would be convincing for most exchanges, including ones where you’re actively looking for tells.
That gap between “afternoon project” and “genuinely hard to detect” is smaller than people assume and it’s shrinking. Better models, larger context windows, cheaper hardware, each of these individually makes impersonation easier; together they compound.
The signals we relied up to now to establish trust in digital communication: name, avatar, writing style, shared history, plausible timing. These signals are all reproducible now, with effort that ranges from an afternoon to a weekend depending on how convincing you want to be.
My grandma always used to say, that history repeats itself and you just have to wait long enough until “old” becomes “new and modern” again. Maybe simple things like code words is something to reconsider in this context, as a last chance to not get tricked.
So please be a little curious about who you’re actually talking to and maybe agree on a code word in case you’re in doubts. And every now and then, just call them…which reminds me, that this might be worth another evening project research ;-).
For the first time the source of a project of mine is not in my repository, as I still fight my inner fight with ethics. ∎




Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.