
Data On Kubernetes
If you’ve attended one of the Kubecon talks or related events, you’ve likely encountered the phrase Data on Kubernetes. To understand what this means, let’s explore some fundamental concepts related to Kubernetes, workload, stateless, and stateful applications.
Kubernetes, workload, stateless and stateful applications
Kubernetes is a container orchestration tool that has already become an industry standard. When we talk about “container orchestration”, we are referring to the automated management and coordination of containers using Kubernetes.
Now, let’s explore what a workload is in the context of Kubernetes. A workload represents an application running on Kubernetes. An application may consist of a single component or multiple components working together. These components are packaged into containers operating within a group of Pods.
There are two types of workloads, depending on the nature of the application: Stateless and Stateful.
In a stateless application, the client session data is not stored on the server. This is because the application doesn’t need to retain past interactions to function. However, in a stateful application, storing client session data is essential as it is necessary for subsequent interactions within the application.
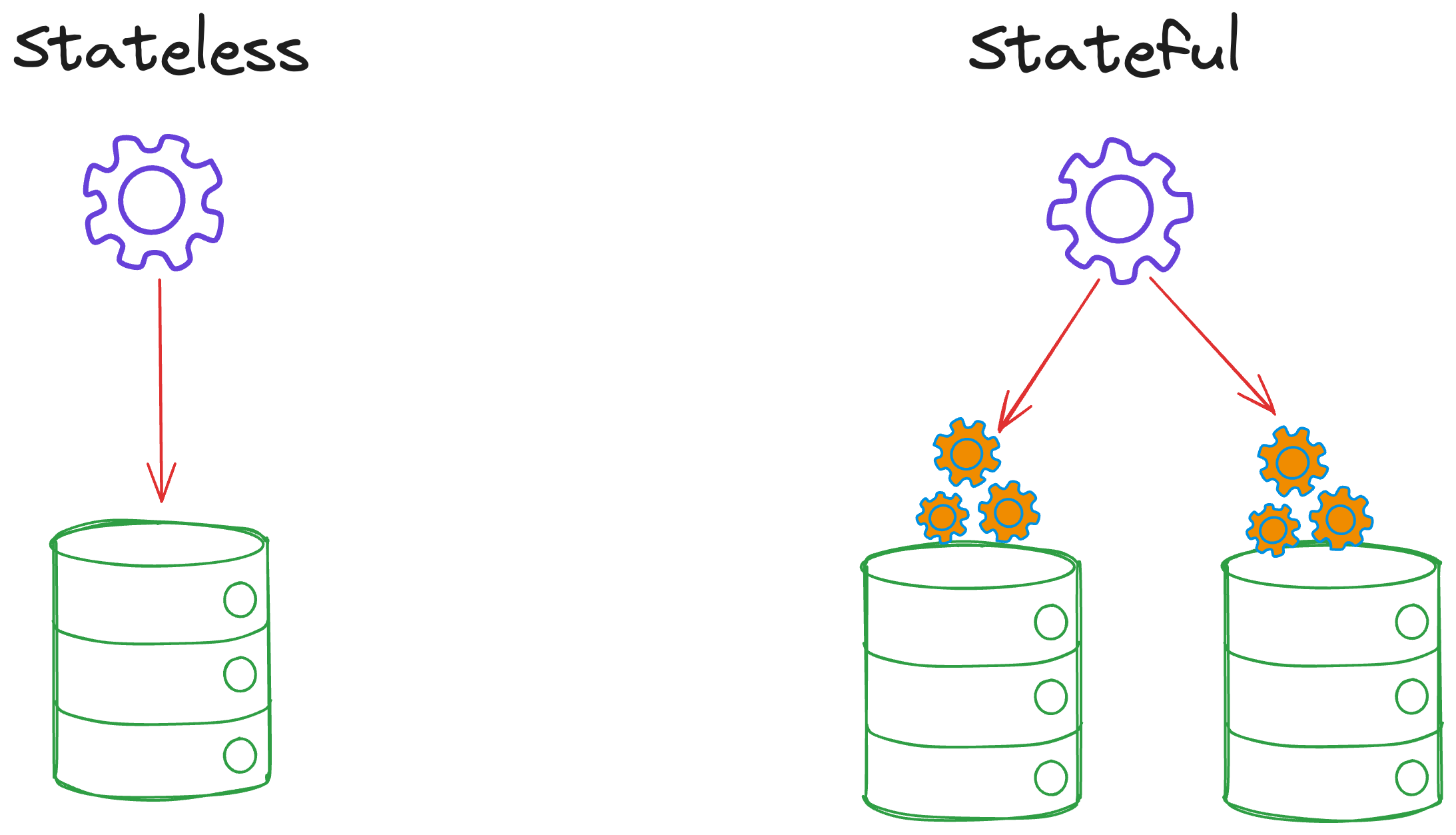
Now, we are already familiar with Kubernetes, workloads, stateless and stateful applications, and we also understand that Pods are responsible for managing these types of workloads.
Built-in Workload Resources in Kubernetes
In a Kubernetes cluster, we can have thousands of Pods, and we don’t need to directly manage them individually. Instead, we utilize workload resources to manage a group of Pods and choose what workload resource depends on the type of workload we are dealing with, Stateless or Stateful.
For example, if we have stateless applications, we can use the Deployment and ReplicaSet resources, which are well-suited for this type of workflow. On the other hand, the StatefulSet resource allows us to run Pods that need to maintain state.
Data on Kubernetes refers to the management and storage of data within the Kubernetes ecosystem. Kubernetes provides a robust framework for handling data, making it a versatile platform for both stateless and stateful applications while ensuring data durability, availability, and security.
The challenge
Kubernetes was initially designed to run stateless applications. However, the number of stateful applications running on Kubernetes has increased significantly. There are many challenges when it comes to running applications with state in Kubernetes, such as data management strategies, volume persistence, and others. According to the 2021 Data on Kubernetes report of more than 500 executives and technology leaders, 90% believe it is ready for stateful workloads, and a large majority (70%) are running them in production, with databases topping the list. This gives rise to initiatives aimed at standardizing the requirements for managing stateful applications on Kubernetes.
This is how Data on the Kubernetes Community emerges. The Data on Kubernetes (DoKc) community was established in spring 2020. It is an openly governed group of curious and experienced practitioners, drawing inspiration from the Cloud Native Computing Foundation (CNCF) and the Apache Software Foundation. They aim to help create and improve techniques for using Kubernetes with data.
There are several organizations that are part of the Data on Kubernetes community, and Percona is part of it as well. Percona is adding efforts in DoKC Operator SIG(Special Interest Groups), where we discuss gaps in information around K8s operators for the industry-at-large & co-creates projects to fill the gap. Watch the Kubernetes Database Operator Landscape panel discussion to learn more about the community efforts in Data on Kubernetes.

Conclusion
Data on Kubernetes is a crucial concept in the Kubernetes ecosystem. Kubernetes was initially designed for the stateless application, now faces the challenge of managing stateful workloads, and is more notable in databases. The Data on Kubernetes (DoKc) community has emerged to address these challenges and standardize the management of stateful applications, drawing inspiration from industry standards like CNCF and Apache Software Foundation.
If you want to be part of them, you are welcome to join DoKC. Also, check this outstanding Kubernetes Database Operators Landscape, where members of DoKC talk about operations for data workloads on Kubernetes. ∎

Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.