
Exploring Kubernetes Operators
The concept of Kubernetes Operators was introduced around 2016 by the CoreOS Linuxdevelopment team. They were in search of a solution to improve automated container management within Kubernetes, primarily with the goal of incorporating operational expertise directly into the software.
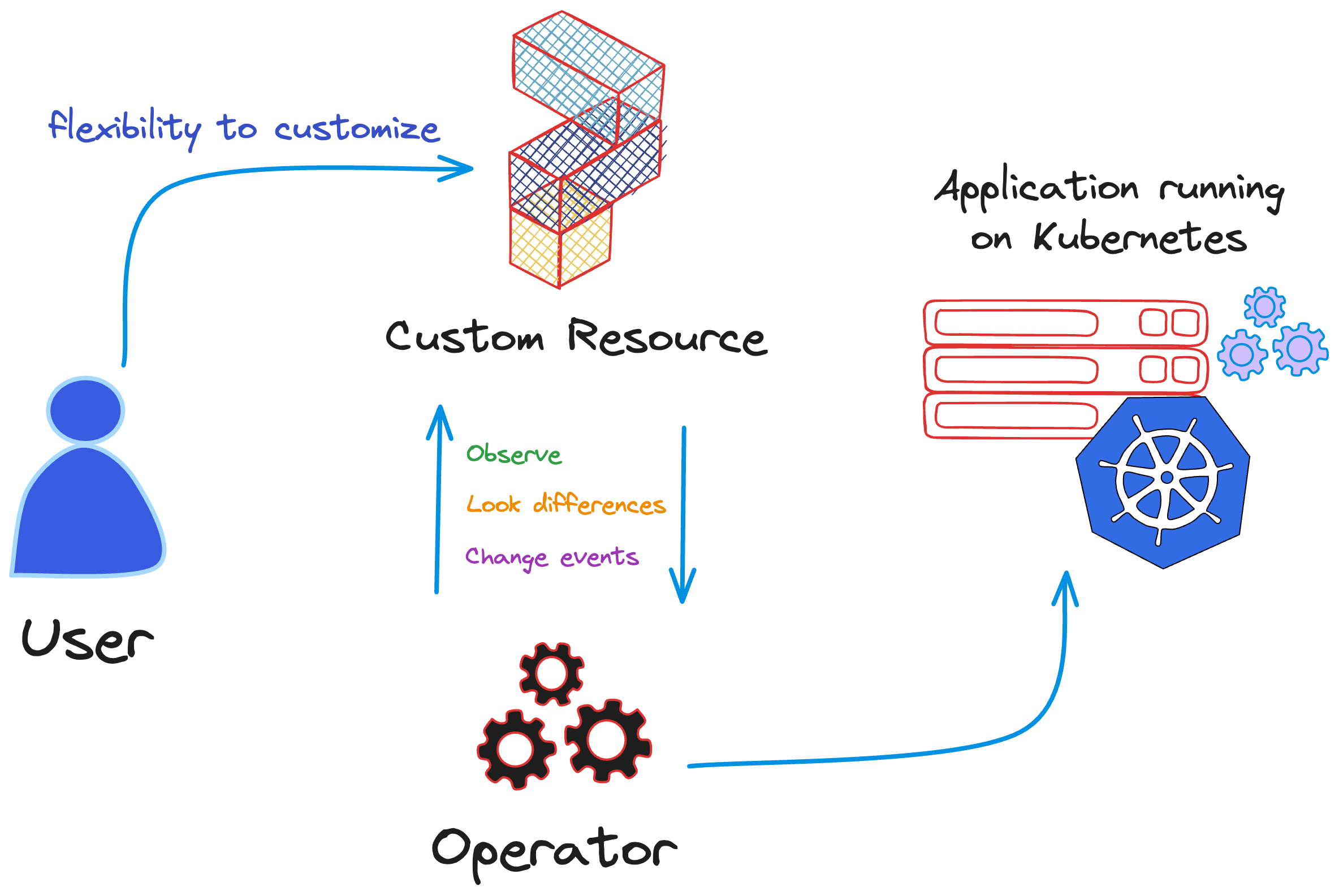
According to the Cloud Native Computing Foundation, “Operators are software extensions that use custom resources to manage applications and their components”.
Kubernetes is designed for automation, offering essential automation features. It can automatically deploy and manage workloads. The definition provided by CNCF regarding operators, as mentioned above, highlights the flexibility we have to customize the automation capabilities made possible by Kubernetes Operators using custom resources.
In Kubernetes, certain applications require manual attention as Kubernetes can not autonomously manage them. This is especially the case with databases. This is where Operators come into play. Databases are complex entities that also have complex database operations and features that Kubernetes itself may not inherently understand. While deploying a database in Kubernetes manually isn’t a problem, the true strength of operators shines during Day 2 operations, which include tasks such as backups, failover, and scaling. Operators automate these manual tasks for applications within Kubernetes.
The main challenge that arises when implementing containerized databases is the problem of data persistence. This is the challenge for containers in general, and it is more critical in the context of databases despite ongoing advances in container maturity. Kubernetes operators are designed to address this gap. While it is possible to use Kubernetes resources like Persistent Volume Claims (PVCs) without operators, operators simplify the process by providing a higher level of abstraction and automation.

It is possible to create new operators using the Kubernetes operator pattern concept. This allows you to extend cluster behavior without modifying the Kubernetes code by linking controllers to one or more custom resources. These Operators use and extend the Kubernetes API, a key component within the Kubernetes architecture, with the essential concepts for users to interact with the Kubernetes cluster. They create custom resources to add new functionality according to the needs of an application to be flexible and scalable. This is how we automate workloads using Kubernetes Operators.
One of the primary benefits of operators is the automation of repetitive tasks that are often managed by human operators, eliminating errors in application lifecycle management.
Conclusion
In this article, we explored an overview of what Kubernetes Operators are; we saw why they are necessary and the benefits of using them. I hope you have gained a general understanding of why Kubernetes Operators are valuable.
If you want to know more about Kubernetes operators designed specifically for databases, you can visit the Percona website, where you will find Kubernetes operators created by Percona for MongoDB, PostgreSQL, and MySQL.
Are you considering creating your own operator? Start by using the Operator-SDK. Additionally, you can watch Sergey Pronin’s (Group Product Manager At Percona) talk at the DoK Community about Migrating MongoDB to Kubernetes, where he discusses the reasons why Percona created an Operator for MongoDB. ∎

Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.