
What experts said at Kubecon about Data on Kubernetes
Melissa Logan, managing director of Data on Kubernetes (DoK), led one of the best panels I’ve been to at a conference at Kubecon EU in Amsterdam about challenges with and the state of the art of running databases on Kubernetes.

This panel united the Data on Kubernetes Community Operator SIG and Kubernetes Storage SIG to discuss key features of Kubernetes database operators. Xing Yang from VMware, Sergey Pronin from Percona, and Álvaro Hernández from OnGres came together to discuss what works, what doesn’t, and where the industry is going. They also presented a feature matrix to help end users compare many database Operators.

If you are new to the topic of Kubernetes Operators, I wrote a blog post about Kubernetes Operators in a nutshell, you can read the first part of this article.
Let’s start by summarizing the challenges the panelists mentioned when running stateful applications on Kubernetes.
Some Operators have certain limitations, and there are security concerns. Database users always think about data encryption: is the data safe? What happens if the node goes down? What happens if we lose the storage?
The Operator model is very extensible and flexible, which is great, but on the other hand, there are so many Operators, and it becomes a challenge to choose the right one for our use cases.
People who are developing Operators also find challenges because every database has its native way of doing backups, but if you want to support more than one type of database, then it’s more challenging to find a generic way.
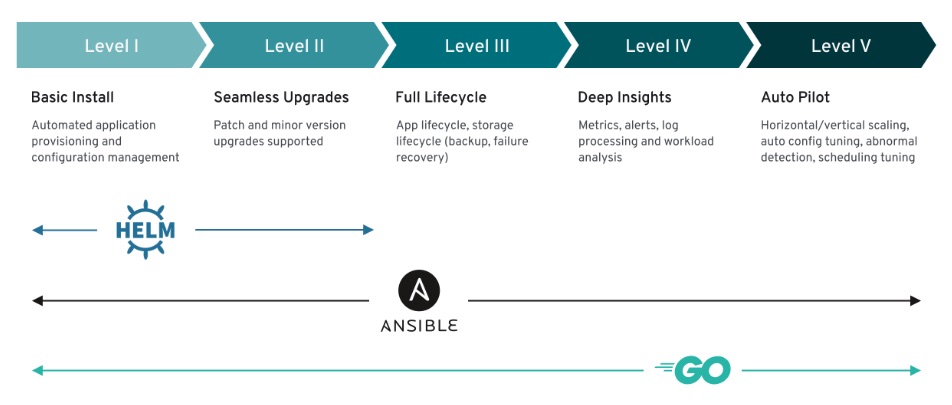
Does the framework capture what is needed for data workloads well?
- There is a capability model for Operators that classify them into five levels. There is room for improvement in this model. It can be improved to build test compatibility and more objective measures of these capability levels if you look at level five, the top one for data workloads.
- Security is the number one criterion that people use to evaluate Operators. How are they addressing security in Kubernetes Operators?
- Users want to ensure that the Operator does not get a lot of privileges or does not interfere with other tenants in the Kubernetes cluster.
- Now users are looking for more sophisticated ways with their existing security key-value storage. They can be sure they are safe.
- The framework should provide ransomware protection, so when you back up your databases, you also want to have one immutable copy to provide your protection and recover from that.
Now Let’s talk about solutions
DoK started an Operator Special Interest Group (SIG), and community members have been meeting to discuss how as a group and as an industry, to collaborate to come up with solutions for some of the challenges end users face. The Operator SIG works with the Storage Technical Advisory Group (TAG), Storage SIG, and Security SIG.
According to data on Kubernetes’s (DoK) first report, 70% of responses are running workloads in production. More data workloads are running on Kubernetes, so it is essential to know what works well. Sharing knowledge and leveraging that expertise is vital at this stage.
There are things that SIG Operators detail in a document, like common patterns and features used when running databases on Kubernetes, best practices, the criteria for running a good operator, why observability is so important in the cloud-native environment and security.
The Operator Feature Matrix is a big initiative to help end users find operators based on different criteria to choose what they need. It is a project to compare different Operators. They are starting with database Operators, and one project is already defined: Postgres Operator Feature Matrix. Feel free to contribute to OFM.
New to Kubernetes Operators and databases? Check out Percona’s Operators for MySQL, PostgreSQL, and MongoDB. ∎

Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.