%22%3E%3Cpath%20d=%22M352.016%20109.322h-18.62v33.317H308.887V31.542h45.54c26.587.0%2042.669%2015.7006%2042.669%2038.4065V70.2514c0%2025.715-20.051%2039.0416-45.051%2039.0416L352.016%20109.322v0zm20.207-38.885C372.223%2059.4847%20364.589%2053.6128%20352.32%2053.6128H333.367V87.5641H352.78c12.27.0%2019.414-7.3081%2019.414-16.8242V70.437H372.223z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M410.776%20142.648V31.542H494.84V53.3001H435.139V75.8497h52.527V97.6078H435.139V120.949h60.494v21.758H410.776V142.648v0z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M582.46%20142.648%20558.588%20107.104H539.331v35.544H514.822V31.542h50.939c26.284.0%2042.032%2013.815%2042.032%2036.6674V68.5123c0%2017.9282-9.702%2029.2128-23.872%2034.4497L611.145%20142.639H582.451L582.46%20142.648zM582.95%2069.4893C582.95%2059.0255%20575.62%2053.603%20563.694%2053.603H539.341V85.5026h24.843C576.12%2085.5026%20582.95%2079.1422%20582.95%2069.8019V69.4991%2069.4893z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M678.058%20145.618c-33.221.0-57.907-25.568-57.907-57.9171V87.3882C620.151%2055.3812%20644.337%2029.1678%20679.048%2029.1678c21.285.0%2034.055%207.0639%2044.54%2017.3616L707.781%2064.6922C699.059%2056.7979%20690.21%2051.9909%20678.891%2051.9909c-19.021.0-32.761%2015.7593-32.761%2035.0652V87.3687c0%2019.3063%2013.397%2035.3683%2032.761%2035.3683C691.788%20122.737%20699.706%20117.588%20708.585%20109.537l15.807%2015.916C712.76%20137.851%20699.863%20145.56%20678.088%20145.56L678.058%20145.618z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M789.963%20145.618c-34.858.0-59.858-25.9-59.858-57.9171V87.3882c0-32.007%2025.333-58.2204%2060.162-58.2204%2034.829.0%2059.858%2025.9007%2059.858%2057.9176V87.398c0%2032.007-25.333%2058.22-60.162%2058.22zm34.212-58.22C824.175%2068.0922%20809.975%2052.03%20789.963%2052.03%20769.952%2052.03%20756.095%2067.7893%20756.095%2087.0951V87.4078C756.095%20106.714%20770.295%20122.776%20790.306%20122.776%20810.318%20122.776%20824.175%20107.017%20824.175%2087.7107V87.398v0z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M985.089%20142.736%201039.93%2029.1678%201094.77%20142.746h-27.5L1039.93%2086.2256l-27.24%2056.5204H985.089V142.736z%22%20fill=%22%23fff%22/%3E%3Cpath%20d=%22M974.936%2031.5811V145.628L891.304%2078.0968V142.551H865.285V29.1678L948.917%2096.4354V31.5811h26.019z%22%20fill=%22%23fff%22/%3E%3C/g%3E%3Cpath%20d=%22M219.315%20146.829c28.718-18.788%2038.114-57.1102%2020.735-87.2301-8.708-15.108-22.784-25.9277-39.624-30.4456-15.602-4.1923-31.898-2.478-46.241%204.7743L134.603.0%2093.9541%2070.4613.0%20233.311H269.206l-49.891-86.482zM195.821%2046.4134c12.241%203.263%2022.427%2011.1294%2028.771%2022.0826%2012.47%2021.5912%205.993%2048.977-14.23%2062.808L163.128%2049.4361c10.176-4.8971%2021.653-5.9652%2032.693-3.0227zM134.603%2035.7593%20238.247%20215.426H177.605L104.268%2088.3409l30.329-52.5762L134.603%2035.7593zM30.9588%20215.426l62.99-109.168L156.939%20215.426H30.9588z%22%20fill=%22url(%23paint0_linear_1391_11470)%22/%3E%3Cpath%20d=%22M306.655%20202.335C306.655%20196.555%20307.958%20191.37%20310.565%20186.78%20313.172%20182.133%20316.713%20178.507%20321.19%20175.9%20325.723%20173.293%20330.738%20171.99%20336.235%20171.99%20342.695%20171.99%20348.333%20173.548%20353.15%20176.665%20357.967%20179.782%20361.48%20184.202%20363.69%20189.925H354.425C352.782%20186.355%20350.402%20183.607%20347.285%20181.68%20344.225%20179.753%20340.542%20178.79%20336.235%20178.79%20332.098%20178.79%20328.387%20179.753%20325.1%20181.68%20321.813%20183.607%20319.235%20186.355%20317.365%20189.925%20315.495%20193.438%20314.56%20197.575%20314.56%20202.335%20314.56%20207.038%20315.495%20211.175%20317.365%20214.745%20319.235%20218.258%20321.813%20220.978%20325.1%20222.905%20328.387%20224.832%20332.098%20225.795%20336.235%20225.795%20340.542%20225.795%20344.225%20224.86%20347.285%20222.99%20350.402%20221.063%20352.782%20218.315%20354.425%20214.745H363.69C361.48%20220.412%20357.967%20224.803%20353.15%20227.92%20348.333%20230.98%20342.695%20232.51%20336.235%20232.51%20330.738%20232.51%20325.723%20231.235%20321.19%20228.685%20316.713%20226.078%20313.172%20222.48%20310.565%20217.89%20307.958%20213.3%20306.655%20208.115%20306.655%20202.335zm130.259%2030.26C431.418%20232.595%20426.403%20231.32%20421.869%20228.77%20417.336%20226.163%20413.738%20222.565%20411.074%20217.975%20408.468%20213.328%20407.164%20208.115%20407.164%20202.335S408.468%20191.37%20411.074%20186.78C413.738%20182.133%20417.336%20178.535%20421.869%20175.985%20426.403%20173.378%20431.418%20172.075%20436.914%20172.075%20442.468%20172.075%20447.511%20173.378%20452.044%20175.985%20456.578%20178.535%20460.148%20182.105%20462.754%20186.695%20465.361%20191.285%20466.664%20196.498%20466.664%20202.335%20466.664%20208.172%20465.361%20213.385%20462.754%20217.975%20460.148%20222.565%20456.578%20226.163%20452.044%20228.77%20447.511%20231.32%20442.468%20232.595%20436.914%20232.595zm0-6.715C441.051%20225.88%20444.763%20224.917%20448.049%20222.99%20451.393%20221.063%20453.999%20218.315%20455.869%20214.745%20457.796%20211.175%20458.759%20207.038%20458.759%20202.335%20458.759%20197.575%20457.796%20193.438%20455.869%20189.925%20453.999%20186.355%20451.421%20183.607%20448.134%20181.68%20444.848%20179.753%20441.108%20178.79%20436.914%20178.79%20432.721%20178.79%20428.981%20179.753%20425.694%20181.68%20422.408%20183.607%20419.801%20186.355%20417.874%20189.925%20416.004%20193.438%20415.069%20197.575%20415.069%20202.335%20415.069%20207.038%20416.004%20211.175%20417.874%20214.745%20419.801%20218.315%20422.408%20221.063%20425.694%20222.99%20429.038%20224.917%20432.778%20225.88%20436.914%20225.88zm134.906-52.7V232H564.085V188.14L544.535%20232H539.095L519.46%20188.055V232H511.725V173.18H520.055L541.815%20221.8l21.76-48.62H571.82zm108.063.0V232H672.148V188.14L652.598%20232H647.158l-19.635-43.945V232H619.788V173.18H628.118l21.76%2048.62%2021.76-48.62H679.883zM735.416%20172.755V210.24C735.416%20215.51%20736.691%20219.42%20739.241%20221.97%20741.848%20224.52%20745.446%20225.795%20750.036%20225.795%20754.57%20225.795%20758.111%20224.52%20760.661%20221.97%20763.268%20219.42%20764.571%20215.51%20764.571%20210.24V172.755H772.306v37.4C772.306%20215.085%20771.315%20219.25%20769.331%20222.65%20767.348%20225.993%20764.656%20228.487%20761.256%20230.13%20757.913%20231.773%20754.145%20232.595%20749.951%20232.595%20745.758%20232.595%20741.961%20231.773%20738.561%20230.13%20735.218%20228.487%20732.555%20225.993%20730.571%20222.65%20728.645%20219.25%20727.681%20215.085%20727.681%20210.155v-37.4H735.416zM866.64%20232H858.905l-31.11-47.175V232H820.06V172.67H827.795l31.11%2047.09V172.67H866.64V232zm55.77-59.245V232H914.675V172.755H922.41zm84.5.0V179.045H990.758V232H983.023V179.045H966.788V172.755h40.122zm85.85.0-19.3%2036.89V232H1065.73V209.645L1046.35%20172.755H1054.93L1069.55%20202.76%201084.17%20172.755H1092.76z%22%20fill=%22%23fff%22/%3E%3Cdefs%3E%3ClinearGradient%20id=%22paint0_linear_1391_11470%22%20x1=%2230.363%22%20y1=%22238.463%22%20x2=%22230.327%22%20y2=%2238.6685%22%20gradientUnits=%22userSpaceOnUse%22%3E%3Cstop%20stop-color=%22%23FC3519%22/%3E%3Cstop%20offset=%221%22%20stop-color=%22%23F0D136%22/%3E%3C/linearGradient%3E%3CclipPath%20id=%22clip0_1391_11470%22%3E%3Crect%20width=%22962.614%22%20height=%22116.656%22%20fill=%22%23fff%22%20transform=%22translate(132.155%2028.9724)%22/%3E%3C/clipPath%3E%3C/defs%3E%3C/svg%3E)
Tarantool is an application server and a database. The server part is written in C, and the user is provided with a Lua interface to use it. Then, Tarantool is an open-source product with its source code in open access, and anyone can develop and distribute Tarantool-based software freely.
Today, I’m going to tell you about an attempt to write my own data structure for the search (the Z-order curve) and build it into the Tarantool ecosystem.
I work as a developer in the Tarantool Solution Team. I don’t create Tarantool but use it extensively. For me, this is an experiment — an attempt to figure out how Tarantool works at a lower level.
What is Tarantool, and where does it store data?
Tarantool is known as an in-memory database (though we have an engine for disk storage too). Engine memtx allows you to store all your data in random access memory and satisfies all ACID principles at the same time.
The equivalent of relational tables in Tarantool is space where tuples are stored. Unlike relational tables, tuples in space can generally have an optional length. Physically, they are stored in a search data structure, with the search key — primary key — is always unique.
Supplementary structures can be built too, i.e. secondary indexes that store only a pointer to a tuple. A secondary index can be not unique, but this is only observable behavior visible to the user. Any index that is not unique is added with primary index fields by default. This way, the stability of tuple sorting inside the index is ensured.
Tarantool supports different types of indexes:
- Firstly, it is B-Tree (B+*-Tree, to be exact). Quite a lot has been written about the structure of [B-Trees]. I would only note that data is stored in a sorted form, making it possible to search by indexed key prefix.
- Index based on a hash table. It will suit you if you don’t need interval selections. The access is by full key. Unlike B-Tree, the time of access to an element is constant, not logarithmical. This index is always unique.
- R-Tree. This type of index is more specialized. It is intended for storing “multidimensional” data, i.e. geographical coordinates. It supports indexing for fields of only one type: array. This is the array of our false coordinates which are ordinary floating-point numbers. It enables search for points located both within and outside a specified border, as well as the nearest neighbors.
- Bitset. It is intended for storing bit arrays in spaces and fulfilling requests using bitmasks.
Z-order curve, or Morton curve
Where the idea to write my own index, a rather exotic one, came from?
Once I stumbled upon Amazon articles [1, 2] telling about the Z-order curve, or Morton curve, structure. This is a scheme for arranging “multidimensional” data inside a flat structure (Z-order curve), which is then fitted into B-Tree. This should help avoid total data scanning. Generally, information about any object having a set of characteristics can be considered multidimensional data. For example, an individual’s height, weight, shoe size, etc. R-Tree is used for this purpose in most databases.
A little bit about how the Z-order curve works.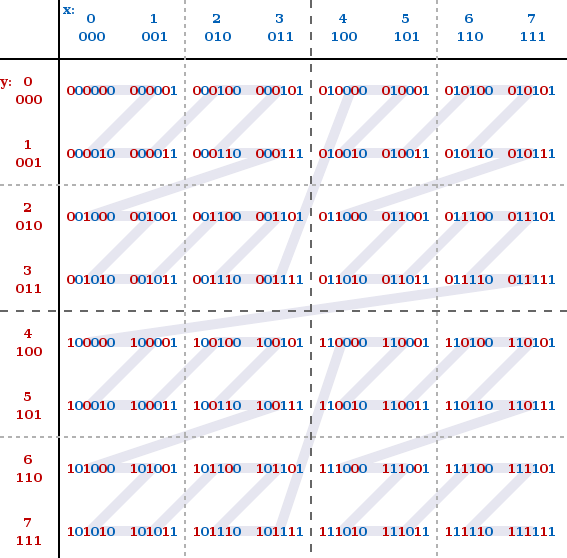
The Z-order curve, or Morton curve, is obtained by interleaving bits of a point’s space coordinates. Z-addresses obtained this way have the property of locality. Points that were adjacent in multidimensional space would normally be located next to each other in projection to a flat line as well.
Schematically, interleaving looks like this: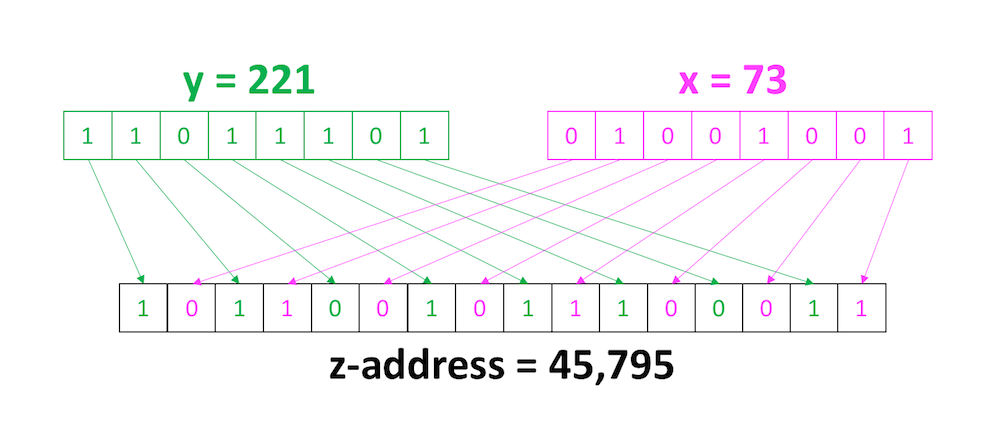
How does it work? We delimit a region in space — hypercube (rectangle, if in two-dimensional space) — using two points located on a diagonal. They are projected on two points on a straight line. And then we see an unpleasant side effect: some points are outside the delimiting rectangle.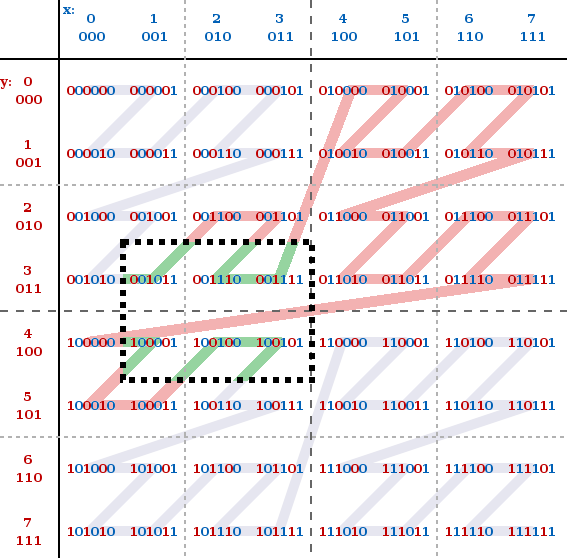
That is, we can’t just iterate with this curve. Fortunately, we can “jump” back to the search area using a special algorithm when we exceed the limits. As soon as we go beyond the end point of the curve (let’s call it upper_bound), the search is over.
In the case of B-Tree, we would have a set of intervals, and sequential scanning of B-Tree would start upon such request. This does take quite a lot of time in the case of a large data set.
There were other publications about this curve that heated up my interest. For example, those about how it was integrated in TransBase [3], a proprietary DB. However, I couldn’t find any open-source implementation of this structure.
B-Tree has an advantage over R-Tree as the basis of this curve: better filling and compact. Drawbacks: Most of the algorithms used are limited by processor. I decided to run a comparison using Tarantool: the focus was on read/insert speed, as well as memory consumption.
What was required for building in Tarantool?
I found simple implementations of this structure for 2-3 dimensions, but I wasn’t interested in small dimensions as I was keen to compare performance with R-Tree index. I chose the same maximum dimensions as with R-Tree in Tarantool, i.e. 20. To do that, I needed a bit array with support for some primitive operations: bit retrieval/alteration, shift, and OR/AND logical operations.
First, I was about to use a borrowed open source-implementation, but soon I realized that I didn’t need a general-use bit array: key length is always equal to 64, so some operations get significantly simplified. I wrote my own implementation. Instead of system memory allocation functions, I began to use special allocators implemented in Tarantool [4].
The heart of index is a set of algorithms for using Z-order curve: computation of Z-address (using special lookup tables), check of whether a Z-address belongs to the search area, and detection of the first entry in the search area starting from a specified point. Research publications describing these algorithms can be found on the Web. I implemented, debugged and optimized them. My plan was to store Z-addresses inside already implemented B-Tree used for the TREE index.
How data handling is arranged?
In the most general case, we have tuple. This is an array of data in message pack format. Ideally, it’s enough to isolate indexed fields, interleave their bits and insert address with a pointer to tuple inside B-Tree.
However, it all would be so easy if we dealt only with the type unsigned, where sorted bit presentations of numbers would correspond to sorted numbers in natural presentation. Signed whole numbers have one set of presentation rules, and floating-point numbers have another. It all had to be combined. Since we store Z-address separately from the data itself, it is possible to make any kind of transformation with our keys, the main thing is to keep the sorting order. This can be done through fairly simple bit manipulations. For instance, for signed whole numbers, the lead byte could just be inverted. For other types, there are similar transformations, though a bit more complex.
All numerical types fit into 8 bytes, so the size of the resulting key will be N * 8 bytes, where N is the dimensions of our space. What to do with strings?
A quite common situation in work with strings is the prefix search. The first 8 bytes of a string can be used as a key. If the string is shorter, it can be added with zeros. Support for strings imposes a fundamental limitation on our index: we lose uniqueness. Even when strings differ in the ninth byte, they still will look the same for the system.
Let’s look at the code.
API of an index comprises a set of methods. Let’s consider only the main ones: search and insert operations.
get — element search by the full key. It works only for unique indexes. Our index cannot be unique, so the function is replaced by a special generic version that returns the “Unsupported index feature" error.
replace — element insertion. Let’s review this in more detail.
static int
memtx_zcurve_index_replace(struct index *base, struct tuple *old_tuple,
struct tuple *new_tuple, enum dup_replace_mode mode,
struct tuple **result)
{
(void)mode;
struct memtx_zcurve_index *index = (struct memtx_zcurve_index *)base;
if (new_tuple) {
struct memtx_zcurve_data new_data;
new_data.tuple = new_tuple;
new_data.z_address = extract_zaddress(new_tuple,
&index->bit_array_pool, index);
struct memtx_zcurve_data dup_data;
dup_data.tuple = NULL;
dup_data.z_address = NULL;
int tree_res = memtx_zcurve_insert(&index->tree, new_data,
&dup_data);
if (tree_res) {
diag_set(OutOfMemory, MEMTX_EXTENT_SIZE,
"memtx_zcurve_index", "replace");
return -1;
}
if (dup_data.tuple != NULL) {
*result = dup_data.tuple;
z_value_free(&index->bit_array_pool, dup_data.z_address);
return 0;
}
}
if (old_tuple) {
struct memtx_zcurve_data old_data, deleted_value;
old_data.tuple = old_tuple;
old_data.z_address = extract_zaddress(old_tuple,
&index->bit_array_pool, index);
memtx_zcurve_delete_value(&index->tree, old_data, &deleted_value);
z_value_free(&index->bit_array_pool, old_data.z_address);
z_value_free(&index->bit_array_pool, deleted_value.z_address);
}
*result = old_tuple;
return 0;
}What should be noted here?
From the index perspective, there is no update, delete, insert, and replace operations. Their whole logic is performed in this method, receiving the old and the new tuples, as well as mode, i.e. information on whether the index is unique or not. Our index cannot be unique, so no additional check is required, and tuple can be inserted at once.
Methods memtx_zcurve_insert and memtx_zcurve_delete_value are methods of the B-Tree which has been already implemented in Tarantool and are used in common TREE index. Unlike a common TREE, we store not just tuple but Z-address as well — interleaved bits of indexed parts. Function extract_zadress is responsible for this.
Method create_iterator: from Lua, we invoke this method in case of select and pairs.
static struct iterator *
memtx_zcurve_index_create_iterator(struct index *base, enum iterator_type type,
const char *key, uint32_t part_count)
{
struct memtx_zcurve_index *index = (struct memtx_zcurve_index *)base;
struct memtx_engine *memtx = (struct memtx_engine *)base->engine;
assert(part_count == 0 || key != NULL);
if (type != ITER_EQ && type != ITER_ALL && type != ITER_GE) {
diag_set(UnsupportedIndexFeature, base->def,
"requested iterator type");
return NULL;
}
uint8_t index_dim = base->def->key_def->part_count;
if (part_count == 0) {
/*
* If no key is specified, downgrade equality
* iterators to a full range.
*/
type = ITER_GE;
key = NULL;
} else if (index_dim * 2 == part_count
&& type != ITER_ALL) {
/*
* If part_count is twice greater than key_def.part_count
* set iterator to a range query
*/
type = ITER_GE;
}
struct tree_iterator *it = mempool_alloc(&memtx->zcurve_iterator_pool);
if (it == NULL) {
diag_set(OutOfMemory, sizeof(struct tree_iterator),
"memtx_zcurve_index", "iterator");
return NULL;
}
iterator_create(&it->base, base);
it->pool = &memtx->zcurve_iterator_pool;
it->base.next = tree_iterator_start;
it->base.free = tree_iterator_free;
it->type = type;
if (part_count == 0 || type == ITER_ALL) {
it->lower_bound = zeros(&index->bit_array_pool, index_dim);
it->upper_bound = ones(&index->bit_array_pool, index_dim);
} else if (type == ITER_EQ) {
it->lower_bound = mp_decode_key(&index->bit_array_pool,
key, index_dim, index);
it->upper_bound = NULL;
} else if (base->def->key_def->part_count == part_count) {
it->lower_bound = mp_decode_key(&index->bit_array_pool,
key, index_dim, index);
it->upper_bound = ones(&index->bit_array_pool, index_dim);
} else if (base->def->key_def->part_count * 2 == part_count) {
it->lower_bound = z_value_create(&index->bit_array_pool, index_dim);
it->upper_bound = z_value_create(&index->bit_array_pool, index_dim);
mp_decode_part(key, part_count, index, it->lower_bound, it->upper_bound);
} else {
unreachable();
}
it->tree_iterator = memtx_zcurve_invalid_iterator();
it->current.tuple = NULL;
it->current.z_address = NULL;
return (struct iterator *)it;
}Depending on the provided key, we compute the lower and the upper request boundaries. However, this iterator points at nothing as yet. There are several types of iterators. In this case, it’s ALL — obtain all elements; EQ — obtain all elements whose Z-address matches the delivered one; and GE — a selection of elements in a hypercube.
destroy — delete index. When the index is secondary, the function frees up memory which was allocated to the search structure. And when the index is primary, it physically deletes stored tuples.
The whole code is available at https://github.com/olegrok/tarantool/tree/z-order-curve-index
Let’s see what we have as a result and draw conclusions.
space = box.schema.space.create('myspace', { engine = 'memtx' })
pk = space:create_index('primary', { type = 'tree', parts = {{1, 'unsigned'}}, unique = true})
sk = space:create_index('secondary', { type = 'zcurve', parts = {{2, 'unsigned'}, {3, 'unsigned'}}})
for i=0,5 do for j=0,5 do space:insert{i * 6 + j, i, j} end end
-- returns all tuples
pk:select{}
-- (2 <= x <= 3) and (3 <= y <= 5)
sk:select{2, 3, 3, 5}
---
- — [15, 2, 3]
- [21, 3, 3]
- [16, 2, 4]
- [22, 3, 4]
- [17, 2, 5]
- [23, 3, 5]
…
-- (x == 2) and (y == 3)
sk:select{2, 3}
---
- — [15, 2, 3]
-- (2 <= x <= 3)
sk:select({2, 3, box.NULL, box.NULL})
---
- — [12, 2, 0]
- [18, 3, 0]
- [13, 2, 1]
- [19, 3, 1]
- [14, 2, 2]
- [20, 3, 2]
- [15, 2, 3]
- [21, 3, 3]
- [16, 2, 4]
- [22, 3, 4]
- [17, 2, 5]
- [23, 3, 5]
...
-- (x >= 2) and (y >= 3)
sk:select({2, box.NULL, 3, box.NULL})
---
- — [15, 2, 3]
- [21, 3, 3]
- [27, 4, 3]
- [33, 5, 3]
- [16, 2, 4]
- [22, 3, 4]
- [17, 2, 5]
- [23, 3, 5]
- [28, 4, 4]
- [34, 5, 4]
- [29, 4, 5]
- [35, 5, 5]
...What about performance?
Not so great, as it turned out.
Starting from some point, the Z-order curve starts losing data access speed considerably. As shown by perf top, most of the time was spent on checking whether a point belonged to the search area, and on computing the next point to jump to. Both operations have linear complexity depending on the key length, i.e. length grows along with growing dimensions.
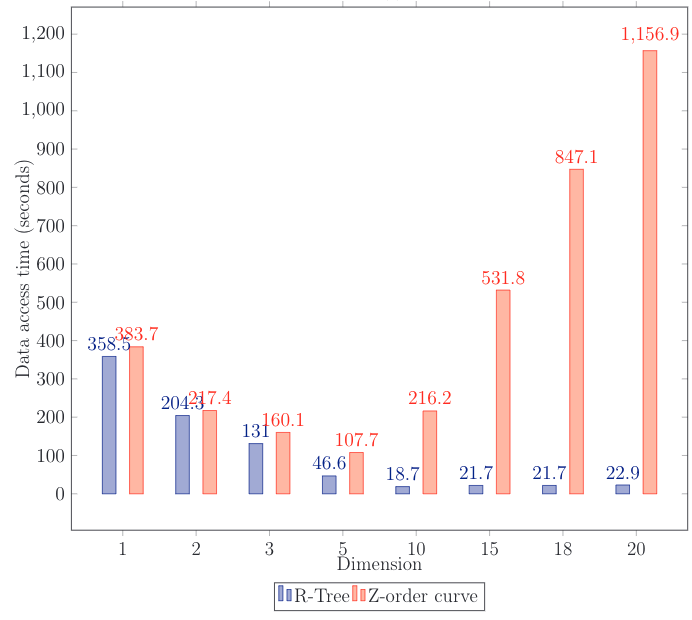
Good news: memory consumption is 2–3 times lower and insertion is slightly faster than with R-Tree. But the measurements were performed with disengaged WAL. In a production environment, disengaged WAL can lead to data loss in case of a fault. On top of that, although WAL writing uses a batch approach, it is still writing to disk, which is thousands of times slower than random access memory operation.
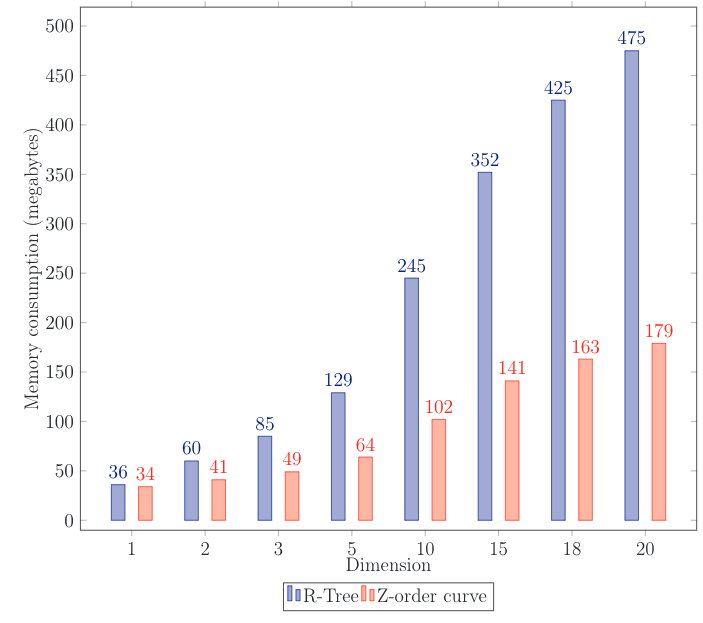
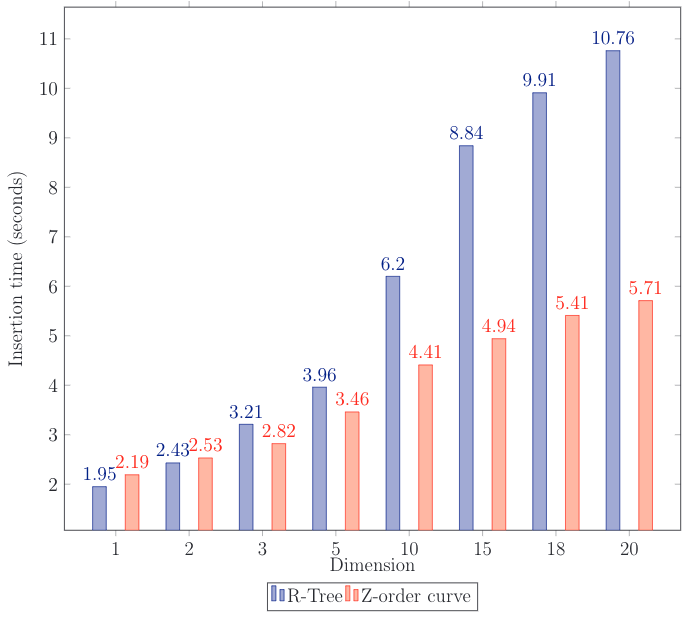
It is also interesting to compare to B-Tree. The curve turned out to be faster than total scanning and checking each point for belonging to the specified area. This is true even though the check is more light-weight than the Z-order curve where it all comes down to bit-wise comparison. Values on the graph differ by order from R-Tree: the test was slightly modified.
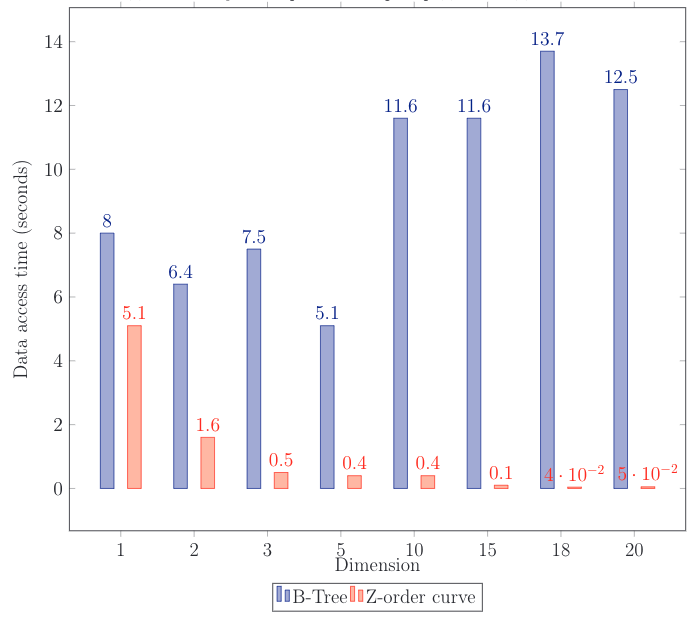
For the test, I generated a set of points and compared time length for request using Z-curve and for ordinary scanning.
Conclusions
The in-memory world didn’t bring out the best in this structure; however, it has some advantages:
- Takes less space.
- Typed, unlike R-Tree (relevant only for Tarantool).
- It makes sense to give it a closer look when only B-Tree is available, and multidimensional requests are required to be made (not relevant for Tarantool).
It was an exciting experiment. Although, the solution I proposed here would hardly become a part of Tarantool.
Sources:
[B-Tree]:
- Indexes PostgreSQL — 4 / Postgres Professional Blog / Habr
- B-tree / Habr
- B-Tree data structure / OTUS Blog. Online education / Habr
[ZcurvePostgres]:

Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.