
IIoT platform databases - How Mail.ru Cloud Solutions deals with petabytes of data coming from a multitude of devices

Our product Mail.ru IoT Platform started as a Tarantool-based prototype. I’m going to tell you about our journey, the problems we faced and the solutions we found. I will also show you a current architecture for the modern Industrial Internet of Things platform. In this article we will look into:
- our requirements for the database, universal solutions, and the CAP theorem
- whether the database + application server in one approach is a silver bullet
- the evolution of the platform and the databases used in it
- the number of Tarantools we use and how we came to this
Mail.ru IoT Platform today
Our product Mail.ru IoT Platform is a scalable and hardware-independent platform for building Industrial Internet of Things solutions. It enables us to collect data from hundreds of thousands devices and process this stream in near real-time by using user-defined rules (scripts in Python and Lua) among other tools.
The platform can store an unlimited amount of raw data from the sources. It also has a set of ready-made components for data visualization and analysis as well as built-in tools for predictive analysis and platform-based app development.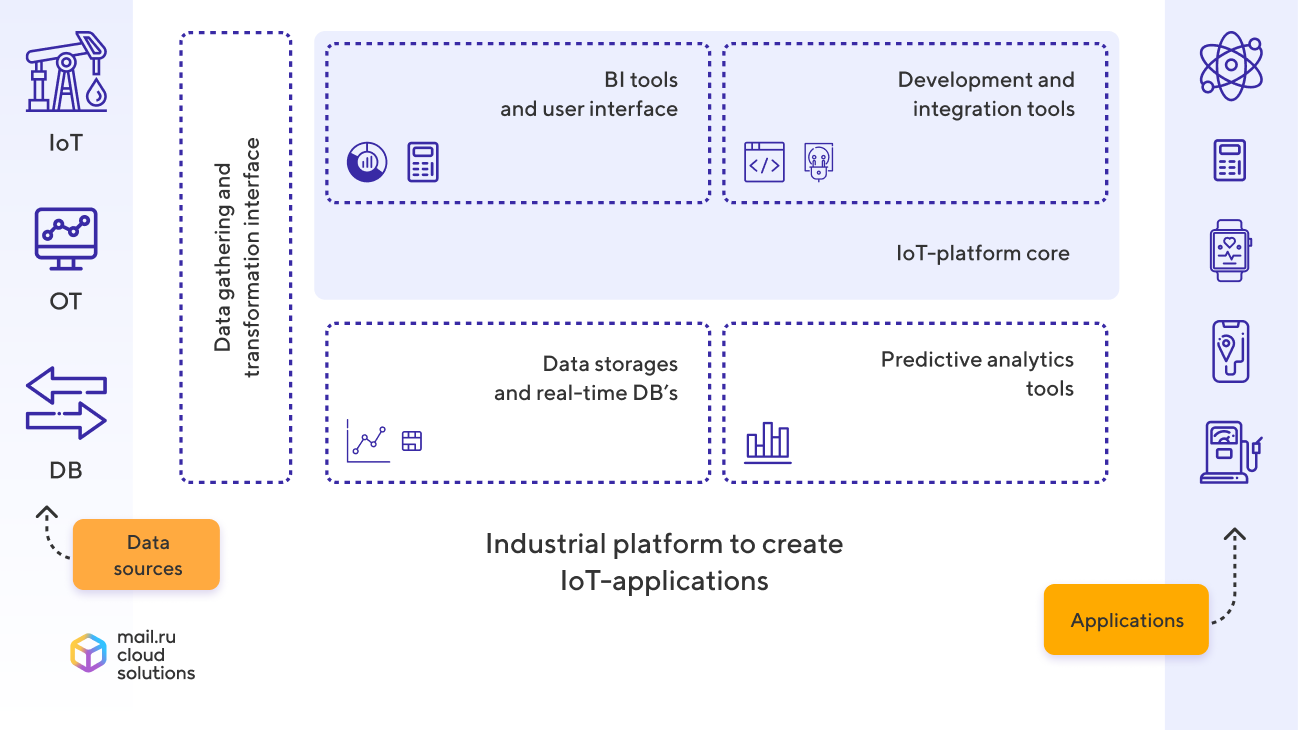
Tarantool-based prototype: how we started
Our platform started as a pilot project – a prototype with a single instance Tarantool. Its primary functions were receiving a data stream from the OPC server, processing the events with Lua scripts in real-time, monitoring key indicators on its basis, and generating events and alerts for upstream systems.
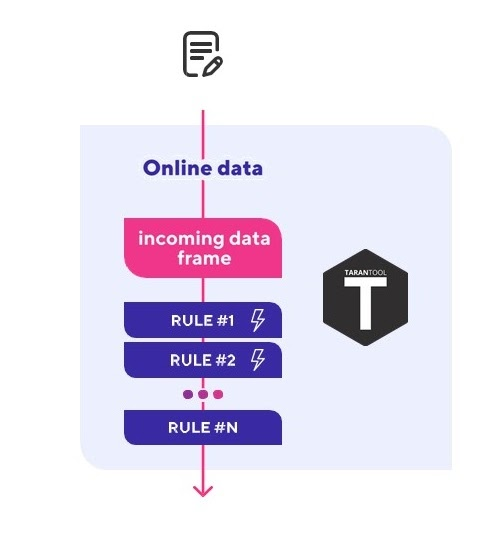
Flowchart of the Tarantool-based prototype[/caption] This prototype has even shown itself in the field conditions of a multi-well pad in Iraq. It worked at an oil platform in the Persian Gulf, monitoring key indicators and sending data to the visualization system and the event log. The pilot was deemed successful, but then, as it often happens with prototypes, it was put into cold storage until we got our hands on it.
Our aims in developing the IoT platform
Along with the prototype, we got ourselves a challenge of creating a fully functional, scalable, and failsafe IoT platform that could then be released as a public cloud service.
We had to build a platform with the following specifications:
- Simultaneous connection of hundreds of thousands of devices
- Receiving millions of events every second
- Datastream processing in near real-time
- Storing several years of raw data
- Analytics tools for both streaming and historic data
- Support for deployment in multiple data centers to maximize disaster tolerance
Pros and cons of the platform prototype
At the start of active development the prototype had the following structure:
- Tarantool that was used as a database + Application Server
- all the data was stored in Tarantool’s memory
- this Tarantool had a Lua app that performed the data reception and processing and called the user scripts with incoming data
This type of app structure has its advantages:
- The code and the data are stored in one place – that enables to manipulate the data right in the application memory and get rid of extra network manipulations, which are typical for traditional apps
- Tarantool uses the JIT (Just in Time Compiler) for Lua. It compiles Lua code into machine code, allowing simple Lua scripts to execute at the C-like speed (40,000 RPS per core and even higher!)
- Tarantool is based upon cooperative multitasking. This means that every call of stored procedure runs in its own coroutine-like fiber. It gives a further performance boost for the tasks with I/O operations, e.g. network manipulations
- Efficient use of resources: tools capable of handling 40,000 RPS per core are quite rare
There are also significant disadvantages:
- We need storing several years of raw data from the devices, but we don’t have hundreds of petabytes for Tarantool
- This item directly results from advantage #1. All of the platform code consists of procedures stored in the database, which means that any codebase update is basically a database update, and that sucks
- Dynamic scaling gets difficult because the whole system’s performance depends on the memory it uses. Long story short, you can’t just add another Tarantool to increase the bandwidth capacity without losing 24 to 32 Gb of memory (while starting, Tarantool allocates all the memory for data) and resharding the existent data. Besides, when sharding, we lose the advantage #1 – the data and the code may not be stored in the same Tarantool
- Performance deteriorates as the code gets more complex with the platform progress. This happens not only because Tarantool executes all the Lua code in a single system stream, but also because the LuaJIT goes into interpreting mode instead of compiling when dealing with complex code
Conclusion: Tarantool is a good choice for creating an MVP, but it doesn’t work for a fully functional, easily maintained, and failsafe IoT platform capable of receiving, processing, and storing data from hundreds of thousands of devices.
Two primary problems that we wanted to solve
First of all, there were two main issues we wanted to sort out:
- Ditching the concept of database + application server. We wanted to update the app code independently of the database.
- Simplifying the dynamic scaling under stress. We wanted to have an easy independent horizontal scaling of the greatest possible number of functions
To solve these problems, we took an innovative approach that was not well tested – the microservice architecture divided into Stateless (the applications) and Stateful (the database).
In order to make maintenance and scaling the Stateless services out even simpler, we containerized them and adopted Kubernetes.
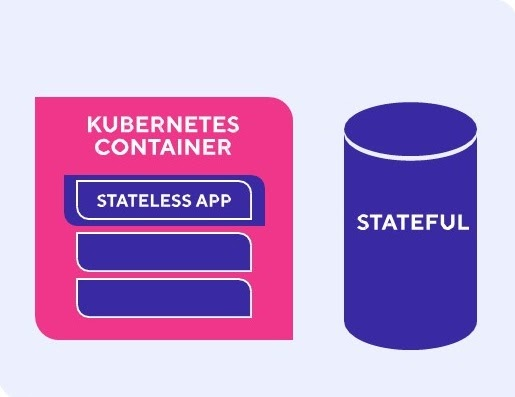
Now that we figured out the Stateless services, we have to decide what to do with the data.
Basic requirements for the IoT platform database
At first, we tried not to overcomplicate things – we wanted to store all the platform data in one single universal database. Having analyzed our goals, we came up with the following list of requirements for the universal database:
- ACID transactions – the clients will keep a register of their devices on the platform, so we wouldn’t want to lose some of them upon data modification
- Strict consistency – we have to get the same responses from all of the database nodes
- Horizontal scaling for writing and reading – the devices send a huge stream of data that has to be processed and saved in near real-time
- Fault tolerance – the platform has to be capable of manipulating the data from multiple data centers to maximize fault tolerance
- Accessibility – no one would use a cloud platform that shuts down whenever one of the nodes fails
- Storage volume and good compression – we have to store several years (petabytes!) of raw data that also needs to be compressed.
- Performance – quick access to raw data and tools for stream analytics, including access from the user scripts (tens of thousands of reading requests per second!)
- SQL – we want to let our clients run analytics queries in a familiar language
Checking our requirements with the CAP theorem
Before we started examining all the available databases to see if they meet our requirements, we decided to check whether our requirements are adequate by using a well-known tool – the CAP theorem.
The CAP theorem states that a distributed system cannot simultaneously have more than two of the following qualities:
- Consistency – data in all of the nodes have no contradictions at any point in time
- Availability – any request to a distributed system results in a correct response, however, without a guarantee that the responses of all system nodes match
- Partition tolerance – even when the nodes are not connected, they continue working independently
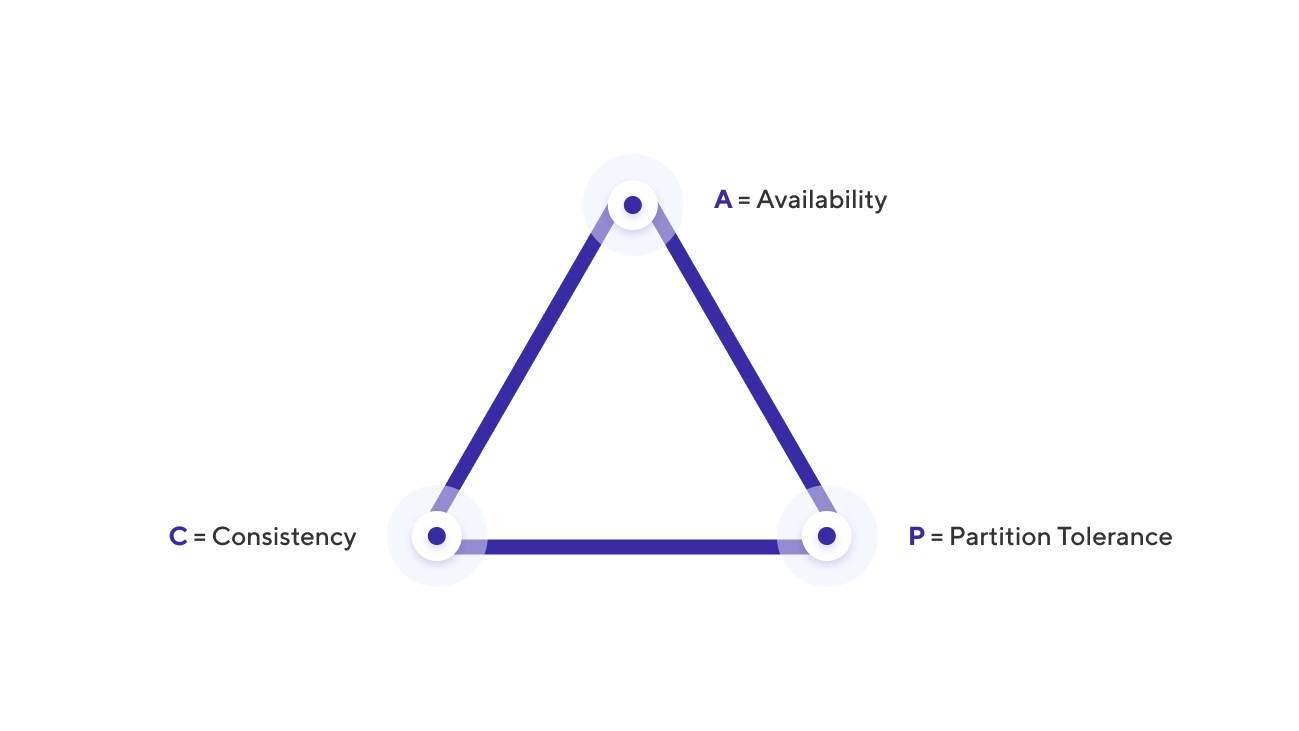
For instance, the Master-Slave PostgreSQL cluster with synchronous replication is a classic example of a CA system and Cassandra is a classic AP system.
Let’s get back to our requirements and classify them with the CAP theorem:
- ACID transactions and strict (or at least not eventual) consistency are C.
- Horizontal scaling for writing and reading + accessibility is A (multi-master).
- Fault tolerance is P: if one data center shuts down, the system should stand.
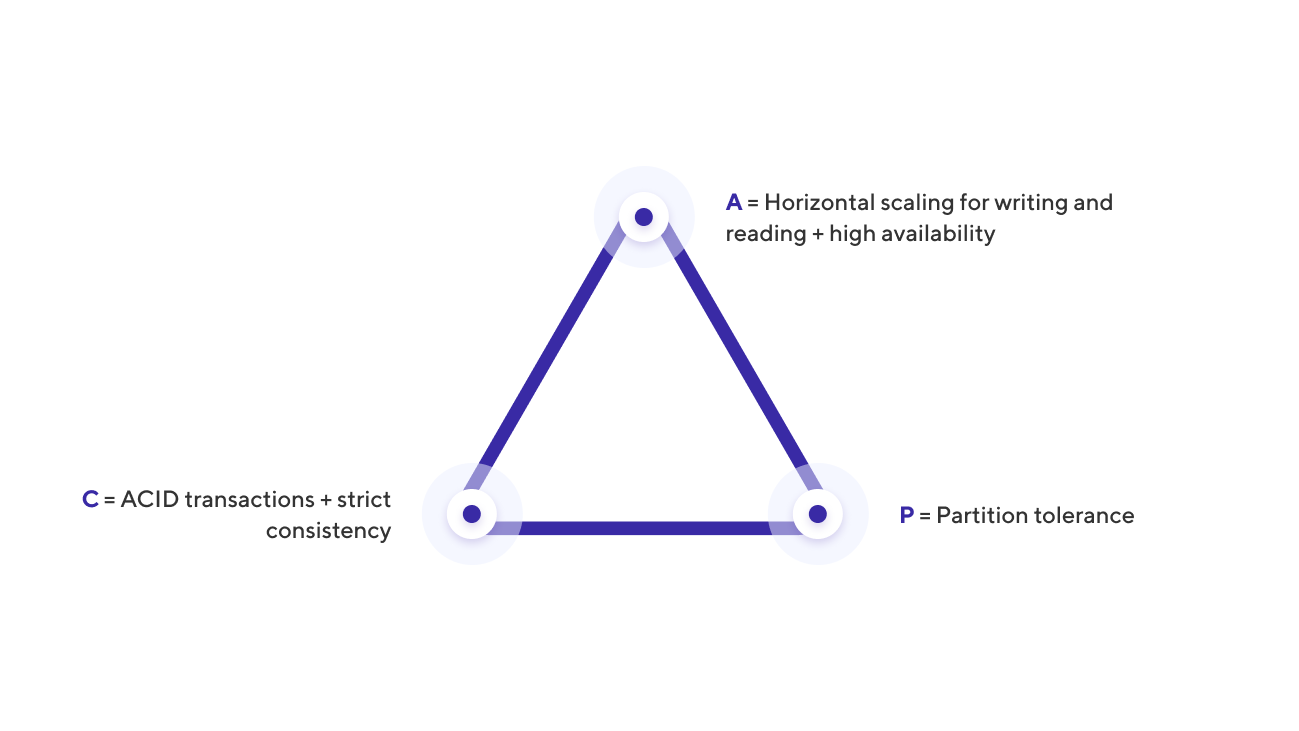
Conclusion: the universal database we require has to offer all of the CAP theorem qualities, which means that none of the existing databases can fulfill all of our needs.
Choosing the database based on the data the IoT platform works with
Being unable to pick a universal database, we decided to split the data into two types and choose a database for each type the database will work with.
With a first approximation we subdivided the data into two types:
- Metadata – the world model, the devices, the rules, the settings. Practically all the data except the data from the end devices
- Raw data from the devices – sensor readings, telemetry, and technical information from the devices. These are time series of messages containing a value and a timestamp
Choosing the database for the metadata
Our requirements
Metadata is inherently relational. It is typical for this data to have a small amount and be rarely modified, but the metadata is quite important. We can’t lose it, so consistency is important – at least in terms of asynchronous replication, as well as ACID transactions and horizontal read scaling.
This data is comparatively little in amount and it will be changed rather infrequently, so you can ditch horizontal read scaling, as well as the possible inaccessibility of the read database in case of failure. That is why, in the language of the CAP theorem, we need a CA system.
What usually works. If we put a question like this, we would do with any classic relational database with asynchronous replication cluster support, e.g. PostgreSQL or MySQL.
Our platform aspects. We also needed support for trees with specific requirements. The prototype had a feature taken from the systems of the RTDB class (real-time databases) – modeling the world using a tag tree. They enable us to combine all the client devices in one tree structure, which makes managing and displaying a large number of devices much easier.
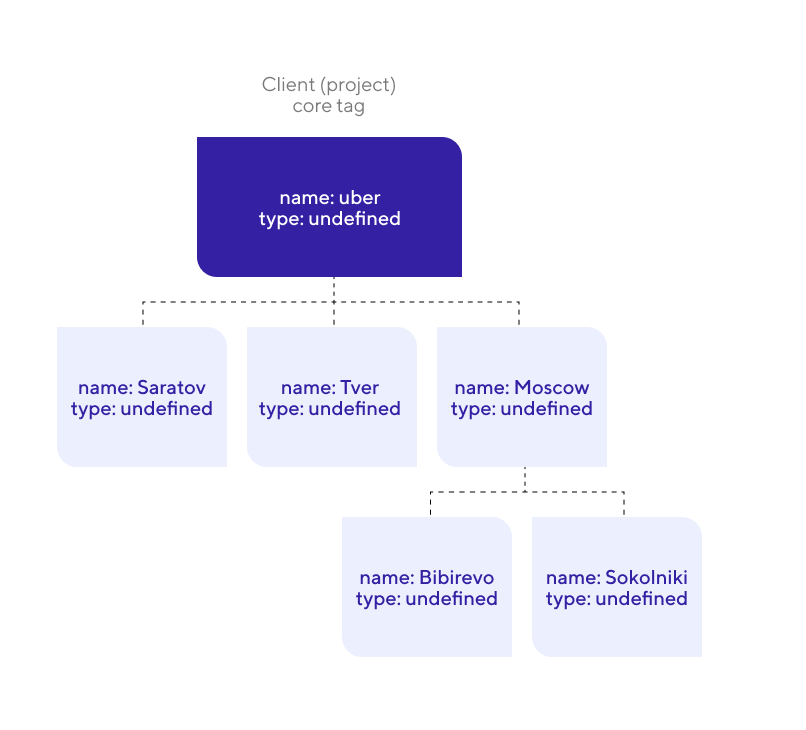
This is how the device tree looks like
This tree enables linking the end devices with the environment. For example, we can put devices physically located in the same room in one subtree, which facilitates the work with them in the future. This function is very convenient, besides, we wanted to work with RTDBs in the future, and this functionality is basically the industry standard there.
To have a full implementation of the tag trees, a potential database must meet the following requirements:
- Support for trees with arbitrary width and depth.
- Modification of tree elements in ACID transactions.
- High performance when traversing a tree.
Classic relational databases can handle small trees quite well, but they don’t do as well with arbitrary trees.
Possible solution. Using two databases: a graph one for the tree and the relational one for all the other metadata.
This approach has major disadvantages:
- To ensure consistency between two databases, you need to add an external transaction coordinator.
- This design is difficult to maintain and not so reliable.
- As a result, we get two databases instead of one, while the graph database is only required for supporting limited functionality.
Our solution for storing metadata. We thought a little longer and remembered that this functionality was initially implemented in a Tarantool-based prototype and it turned out very well.
Before we continue, I would like to give an unorthodox definition of Tarantool: Tarantool is not a database, but a set of primitives for building a database for your specific case.
Available primitives out of the box:
- Spaces – an equivalent of tables for storing data in the databases.
- Full-fledged ACID transactions.
- Asynchronous replication using WAL logs.
- A sharding tool that supports automatic resharding.
- Ultrafast LuaJIT for stored procedures.
- Large standard library.
- LuaRocks package manager with even more packages.
Our CA solution was a relational + graph Tarantool-based database. We assembled perfect metadata storage with Tarantool primitives:
- Spaces for storage.
- ACID transactions – already in place.
- Asynchronous replication – already in place.
- Relations – we built them upon stored procedures.
- Trees – built upon stored procedures too.
Our cluster installation is classic for systems like these – one Master for writing and several Slaves with asynchronous replications for reading scaling.
As a result, we have a fast scalable hybrid of relational and graph databases.
One Tarantool instance is able to process thousands of reading requests, including those with active tree traversals.
Choosing the database for storing the data from the devices
Our requirements
This type of data is characterized by frequent writing and a large amount of data: millions of devices, several years of storage, petabytes of both incoming messages, and stored data. Its high availability is very important since the sensor readings are important for the user-defined rules and our internal services.
It is important that the database offers horizontal scaling for reading and writing, availability, and fault tolerance, as well as ready-made analytical tools for working with this data array, preferably SQL-based. We can sacrifice consistency and ACID transactions, so in terms of the CAP theorem, we need an AP system.
Additional requirements. We had a few additional requirements for the solution that would store the gigantic amounts of data:
- Time Series – sensor data that we wanted to store in a specialized base.
- Open-source – the advantages of open source code are self-explanatory.
- Free cluster – a common problem among modern databases.
- Good compression – given the amount of data and its homogeneity, we wanted to compress the stored data efficiently.
- Successful maintenance – in order to minimize risks, we wanted to start with a database that someone was already actively exploiting at loads similar to ours.
Our solution. The only database suiting our requirements was ClickHouse – a columnar time-series database with replication, multi-master, sharding, SQL support, and a free cluster. Moreover, Mail.ru has many years of successful experience in operating one of the largest ClickHouse clusters.
But ClickHouse, however good it may be, didn’t work for us.
Problems with the database for device data and their solution
Problem with writing performance. We immediately had a problem with the large data stream writing performance. It needs to be delivered to the analytical database as soon as possible so that the rules analyzing the flow of events in real-time can look at the history of a particular device and decide whether to raise an alert or not.
Solution. ClickHouse is not good with multiple single inserts, but works well with large packets of data, easily coping with writing millions of lines in batches. We decided to buffer the incoming data stream, and then paste this data in batches.
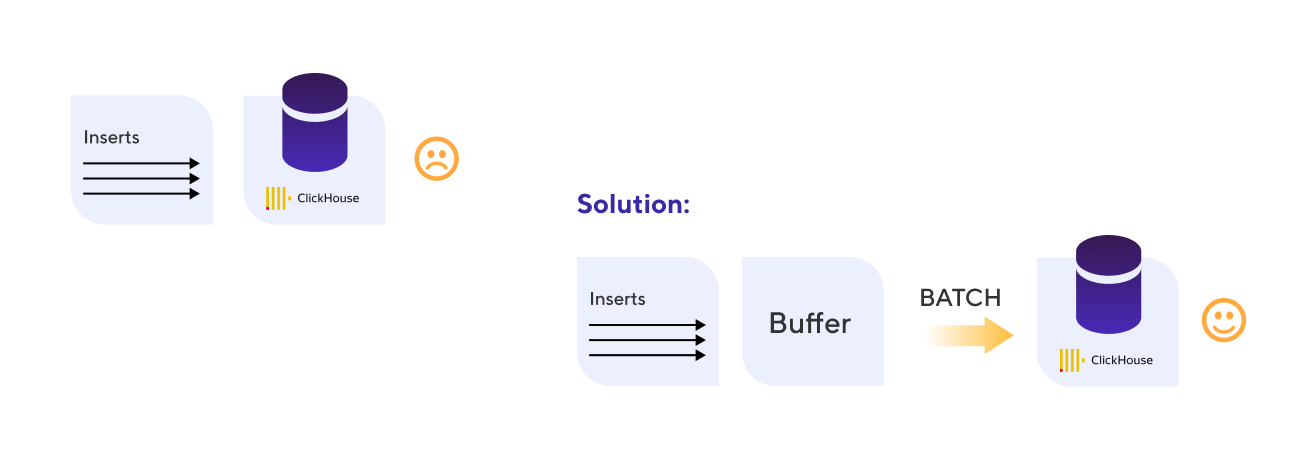
This is how we dealt with poor writing performance
The writing problems were solved, but it cost us several seconds of lag between the data coming into the system and its appearance in our database.
This is critical for various algorithms that react to the sensor readings in real-time.
Problem with reading performance. Stream analytics for real-time data processing constantly needs information from the database – tens of thousands of small queries. On average, one ClickHouse node handles about a hundred analytical queries at any time. It was created to infrequently process heavy analytical queries with large amounts of data. Of course, this is not suitable for calculating trends in the data stream from hundreds of thousands of sensors.
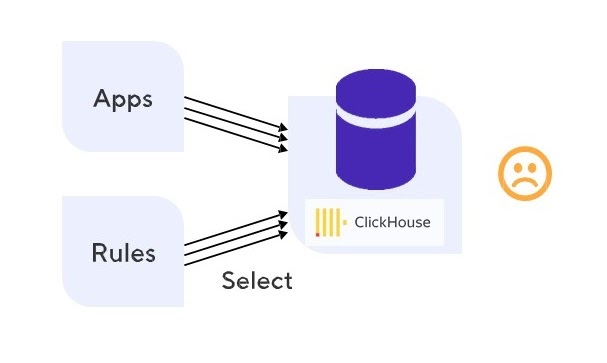
ClickHouse doesn’t handle a large number of queries well
Solution. We decided to place a cache in front of Clickhouse. The cache was meant to store the hot data that has been requested in the last 24 hours most often.
24 hours of data is not a year but still quite a lot – so we need an AP system with horizontal scaling for reading and writing and a focus on performance while writing single events and numerous readings.
We also need high availability, analytic tools for time series, persistence, and built-in TTL. So, we needed a fast ClickHouse that could store everything in memory. Being unable to find any suitable solutions, we decided to build one based on the Tarantool primitives:
- Persistence – check (WAL-logs + snapshots).
- Performance – check; all the data is in the memory.
- Scaling – check; replication + sharding.
- High availability – check.
- Analytics tools for time series (grouping, aggregation, etc.) – we built them upon stored procedures.
- TTL – built upon stored procedures with one background fiber (coroutine).
The solution turned out to be powerful and easy to use. One instance handled 10,000 reading RPCs, including analytic ones.
Here is the architecture we came up with:
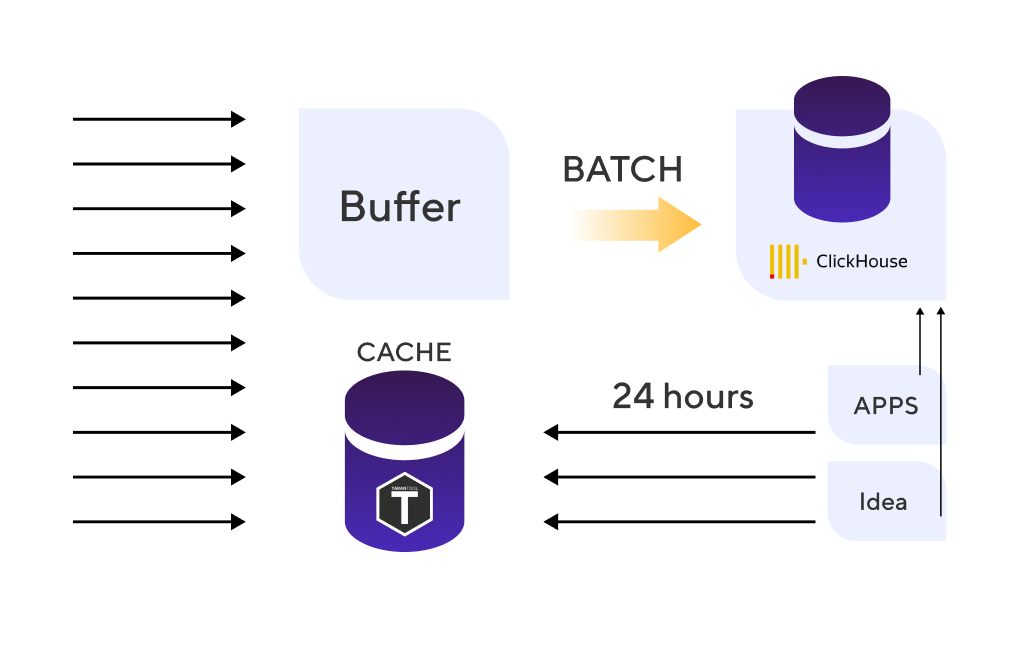
Final architecture: ClickHouse as the analytic database and the Tarantool cache storing 24 hours of data.
A new type of data – the state and it’s storing
We found a specific database for each type of data, but as the platform developed, another one appeared – the status. The status consists of current statuses of sensors and devices, as well as some global variables for stream analytics rules.
Let’s say we have a lightbulb. The light may be either on or off, and we always need to have access to its current state, including one in the rules. Another example is a variable in stream rules – e.g., a counter of some sort.
This type of data needs frequent writing and fast access but doesn’t take a lot of space.
Metadata storage doesn’t suit this type of data well, because the status may change quite often and we only have one Master for writing. Durable and operating storage doesn’t work well too, because our status was last changed three years ago, and we need to have quick reading access.
This means that the status database needs to have horizontal scaling for reading and writing, high availability, fault tolerance, and consistency on the values/documents level. We can sacrifice global consistency and ACID transactions.
Any Key-Value or a document database should work: Redis sharding cluster, MongoDB, or, once again, Tarantool.
Tarantool advantages:
- It is the most popular way of using Tarantool.
- Horizontal scaling – check; asynchronous replication + sharding.
- Consistency on the document level – check.
As a result, we have three Tarantools that are used differently: one for storing metadata, a cache for quick reading from the devices, and one for storing status data.
How to choose a database for your IoT platform
- There is no such thing as a universal database.
- Each type of data should have its own database, the one most suitable.
- There is a chance you may not find a fitting database in the market.
- Tarantool can work as a basis for a specialized database

Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.