
Making a Tarantool-Based Investment Business Core for Alfa-Bank
A still from “Our Secret Universe: The Hidden Life of the Cell”
Investment business is one of the most complex domains in the banking world. It’s about not just credits, loans, and deposits — there are also securities, currencies, commodities, derivatives, and all kinds of complex stuff like structured products.
Recently, people have become increasingly aware of their finances. More and more get involved in securities trading. Individual investment accounts have emerged not so long ago. They allow you to trade in securities and get tax credits or avoid taxes at the same time. All clients coming to us want to manage their portfolios and see their reporting on-line. Most frequently, these are multi-product portfolios, which means that people are clients of different business areas.
Moreover, the demands of regulators, both Russian and international, also grow.
To meet the current needs and lay a foundation for future upgrades, we’ve developed our Tarantool-based investment business core.
A few statistics: Alfa Bank’s investment business provides brokerage services to individuals and entities enabling them to trade in various securities markets; custody services holding their securities; trust management services for big private capital owners, and securities emission services to other companies. Talking about Alfa Bank’s investment business, we mean over 3 thousand quotations per second which come from different trading platforms. Over 300 thousand transactions per trading day are closed on behalf of the bank or its clients. There are up to 5 thousand orders executed every second on domestic and international platforms. On top of that, all clients, both domestic and international, want to see their positions in real-time.
Background
Starting from the early 2000s, our investment businesses are developing independently: exchange business, brokerage services, currency trading, and over-the-counter trading in securities and various derivatives. As a result, we got into the pitfall of functional wells. What is it? Each business area has its systems that duplicate each other’s functions. Each system has its own data model, although they use one and the same concepts: transactions, instruments, counterparties, quotations, and others. As each system has developed independently, a diverse “technology zoo” has emerged.
Additionally, the systems’ codebase has become rather old, because some products were conceived back in the mid-1990s. This deterred the development process, and there were performance issues.
Requirements for a new solution
Those in the business realized that a technology transformation was vital for continued growth. We were assigned the following tasks:
- Collect all business data in a single fast storage and within a single data model.
- The data should not be lost or modified.
- The data had to be versioned because the regulator could request historical data for past years at any time.
- We had not just to create some new fancy database management system but to make a platform for delivering on business objectives.
Apart from that, our architects named their own terms:
- The new solution should be enterprise-class, which means it should have been already proven in a major business.
- The solution’s operation should be mission-critical. This means we should be present in several data centers at the same time and safely survive the shutdown of a single data center.
- The system should be horizontally scalable. In fact, all our current systems are only vertically scalable, and we already have no room for further growth due to low rates of hardware performance enhancement. So, we are now at the point where we need to have a horizontally scalable system to survive.
- Apart from that, we were told that the solution should be cost-efficient.
We followed a standard approach: specified the requirements and contacted our procurement unit. From them, we received a list of companies that generally agreed to do that for us. We told them all about the assignment and received solution quotations from six of them.
We in the banking business take no one’s word for anything and like to test everything ourselves. Thus, it was a prerequisite for the bidders to pass load tests. We specified load testing assignments, and three companies of six agreed to implement a prototype solution for their own account on the basis of in-memory technology for testing.
I won’t tell here how we were testing everything and how much time it took, just the final result: a prototype Tarantool-based solution from Mail.ru Group’s developers’ team showed the best performance in loading tests. We signed a contract and started development. There were four developers from Mail.ru Group and three from Alfa Bank, three system analysts, a solution architect, a product owner, and a Scrum master.
Now I’m going to tell you how our system grew and evolved, and what we did, and why.
Development
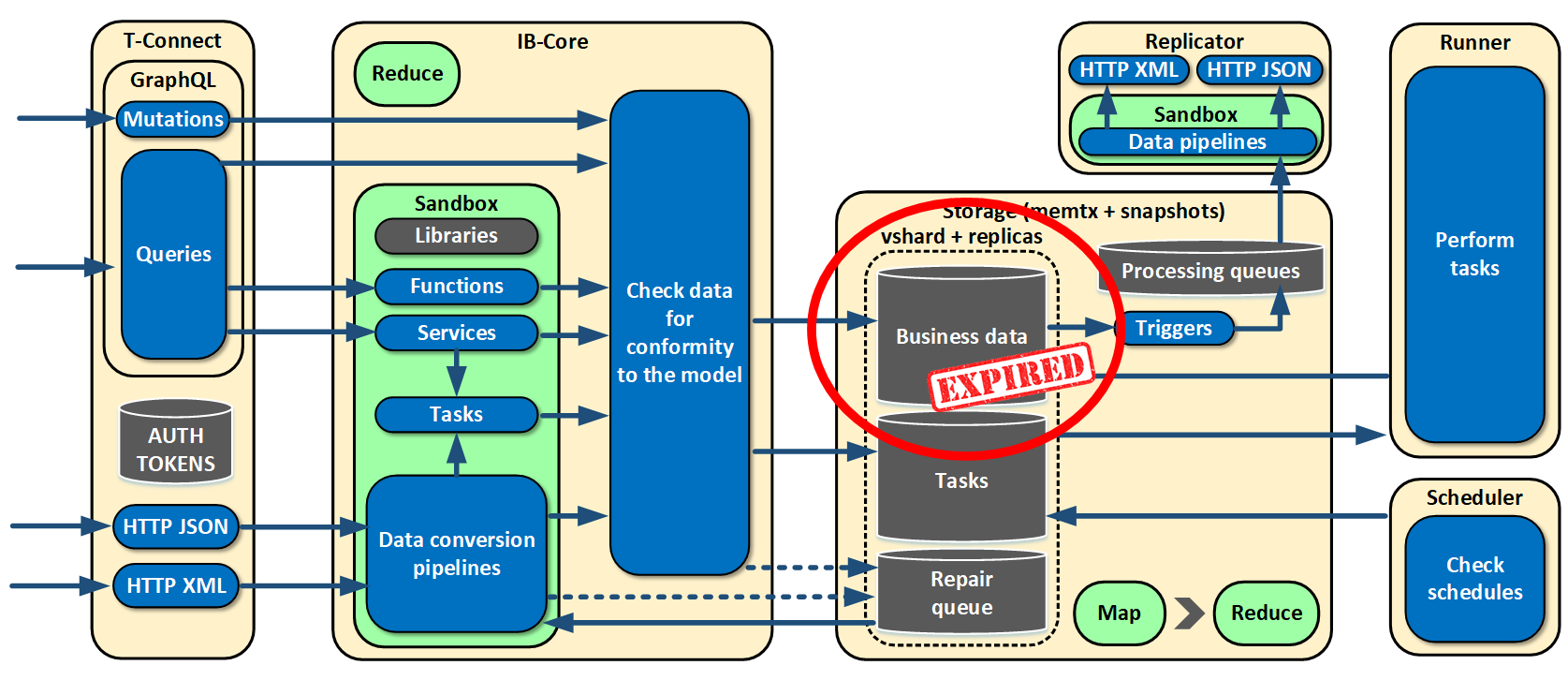
First, we asked ourselves a question about how to retrieve data from our current systems. We concluded that HTTP was quite suitable because all the current systems communicated with each other sending XML or JSON via HTTP.
We use an HTTP server built into Tarantool because we have no need to terminate SSL sessions — its capacity is more than enough.
As I already said, all our systems exist in different data models, and, at the input, we need to bring the object to the model that we specify for us. We needed a language enabling data conversion. We chose imperative Lua. We execute all the code for data conversion in a sandbox — it’s a safe place from which the running code cannot escape. To do that, we simply make a load string of the desired code, creating an environment with features that cannot block or disrupt anything.
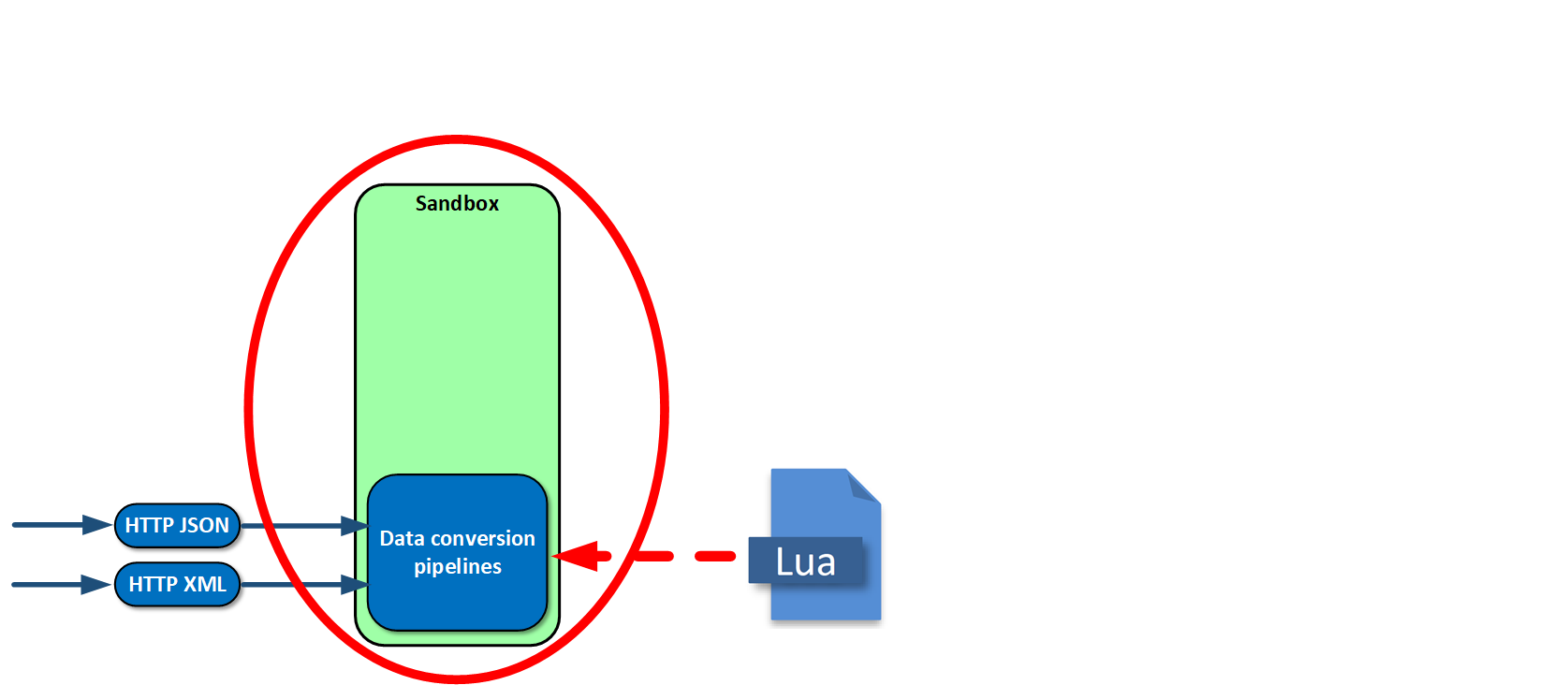
After conversion, data needs to be checked for conformity to the model we are creating. We had a long discussion of what the model should look like, and what language to use to define it. Our final choice was Apache Avro because it is a simple language supported by Tarantool. New versions of the model and custom code can be sent to operation several times a day, load or no load, round the clock, and we can adjust to changes really fast.
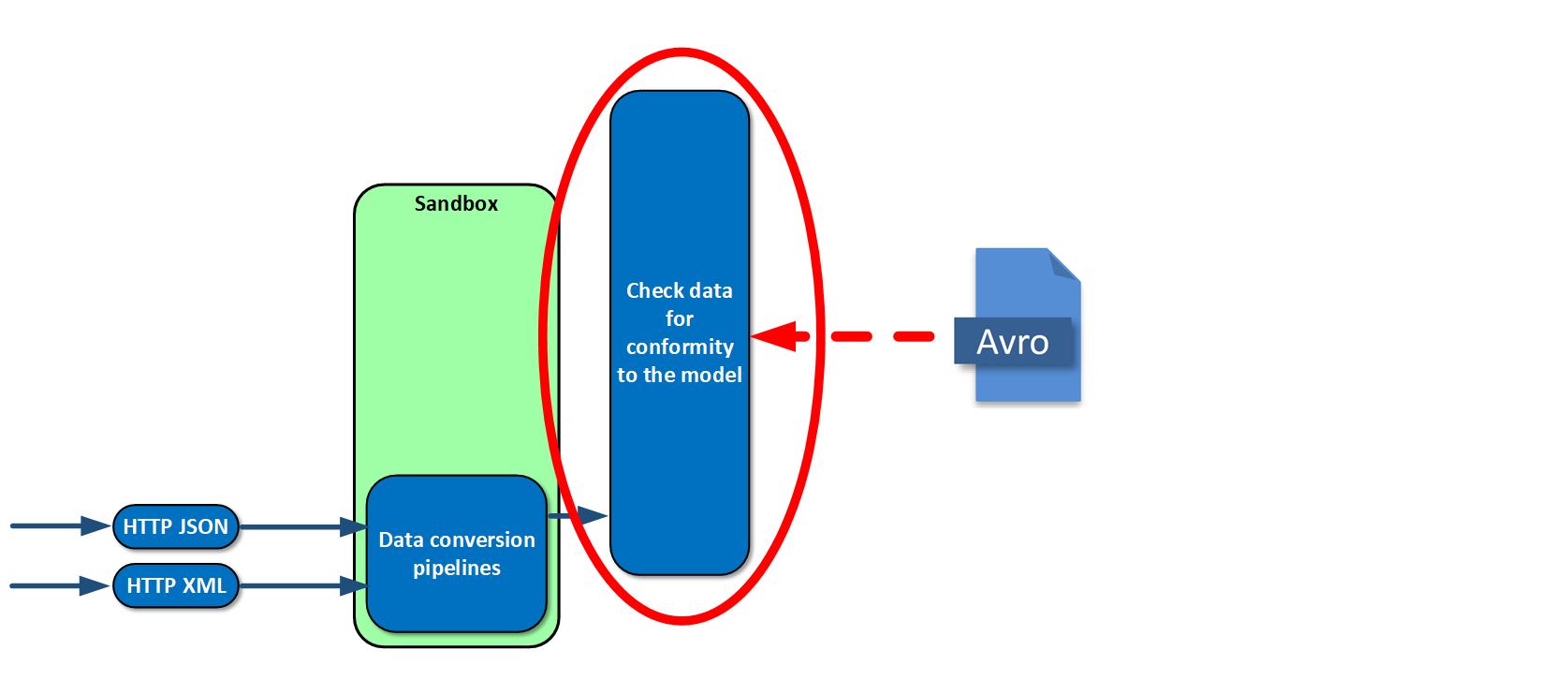
After checking, the data needs to be saved. We do this using vshard (we have geographically dispersed replica shards).
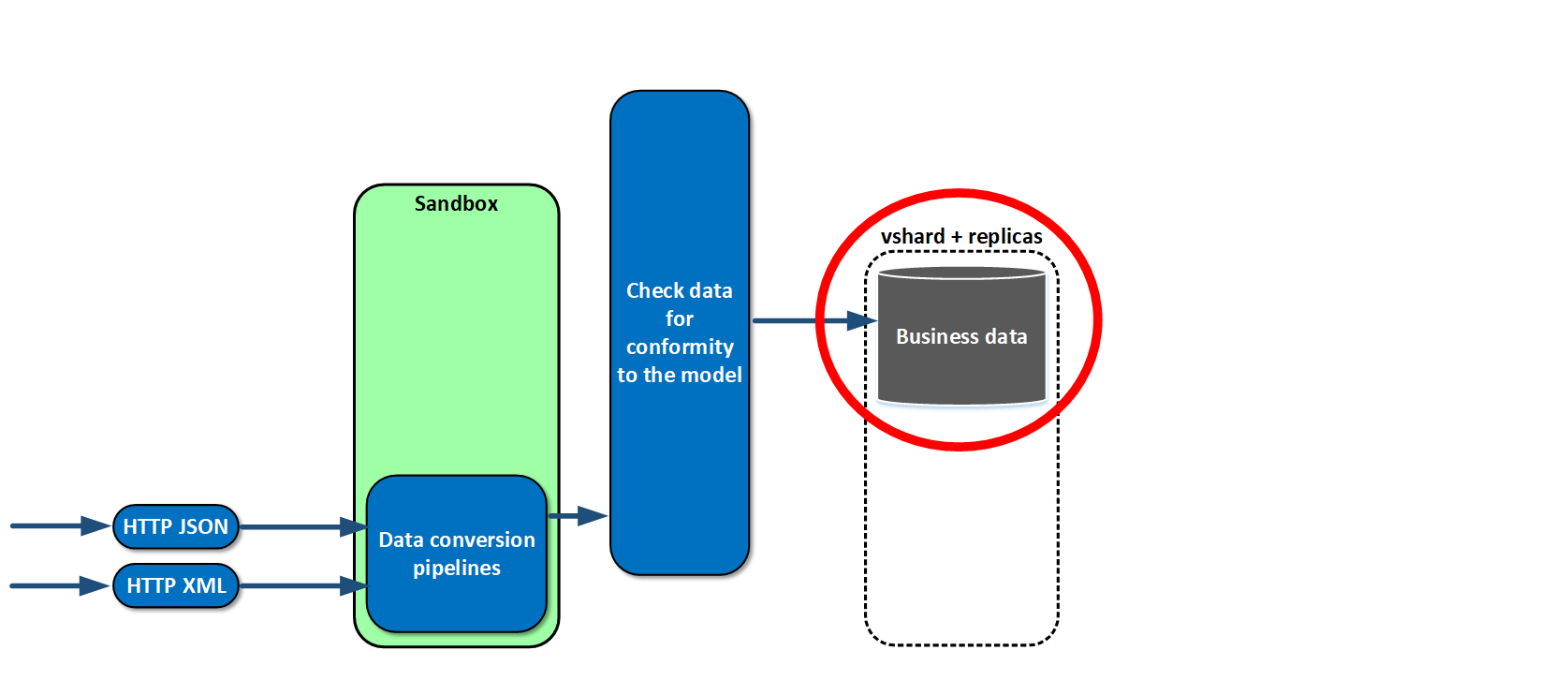
What is special about this is that most systems that send data to us don’t care if we receive the data or not. So we implemented a repair queue in the very beginning. What is it? If for some reason, an object has not passed data conversion or check, we confirm receipt anyway but save the object in the repair queue. It is coherent and is located in basic storage with business data. We wrote the admin interface, various metrics, and alerts for it early on. As a result, we don’t lose data. Even if something changes in the source, if data model changes, we can notice this at once and adjust accordingly.
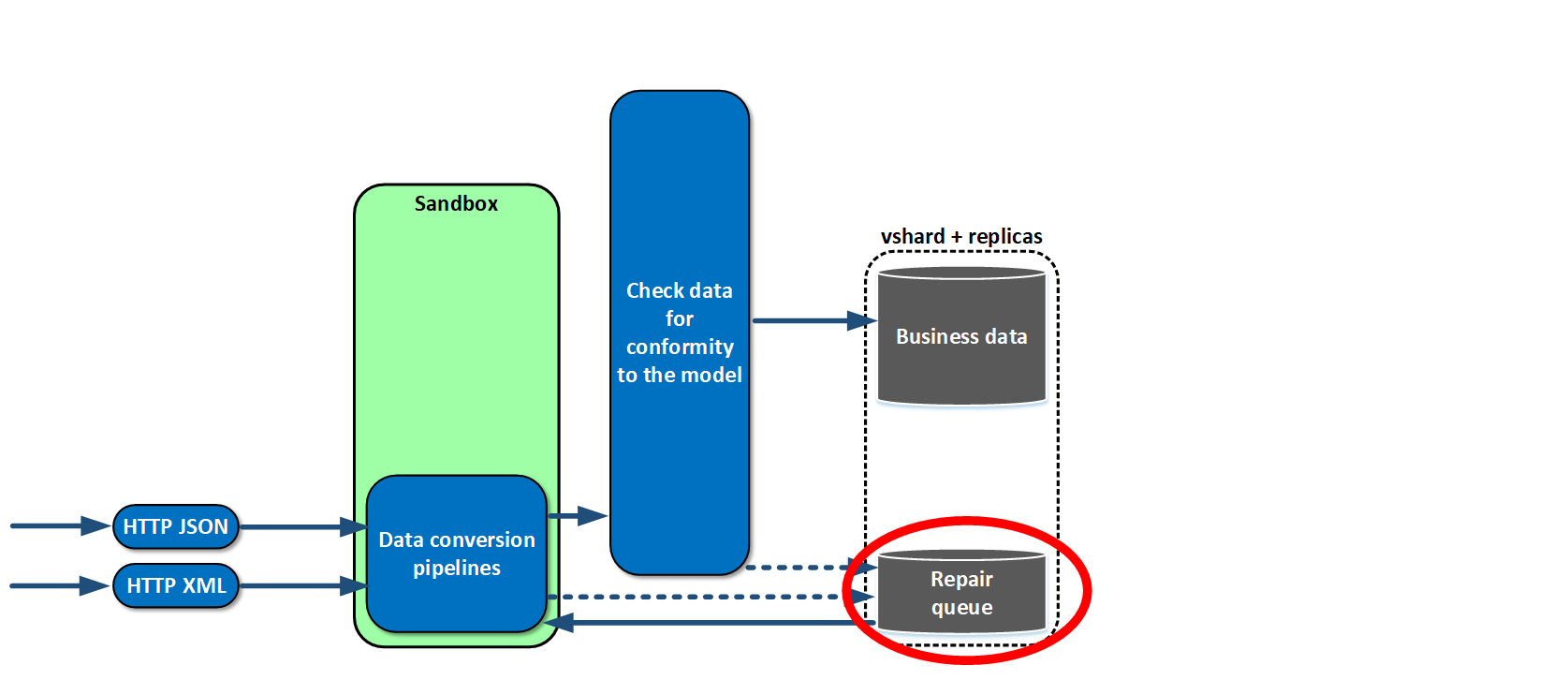
Now we have to learn how to retrieve the saved data. We gave our systems a thorough review and saw that on a classic stack from Java and Oracle there was always some ORM that converted relational data to object data. So why not just feed objects to systems in the form of a graph? That is why we gladly chose GraphQL which satisfied our needs. It enables data to be obtained in the form of graphs and retrieve only what is needed at the moment. Even API can be versioned with sufficient flexibility.
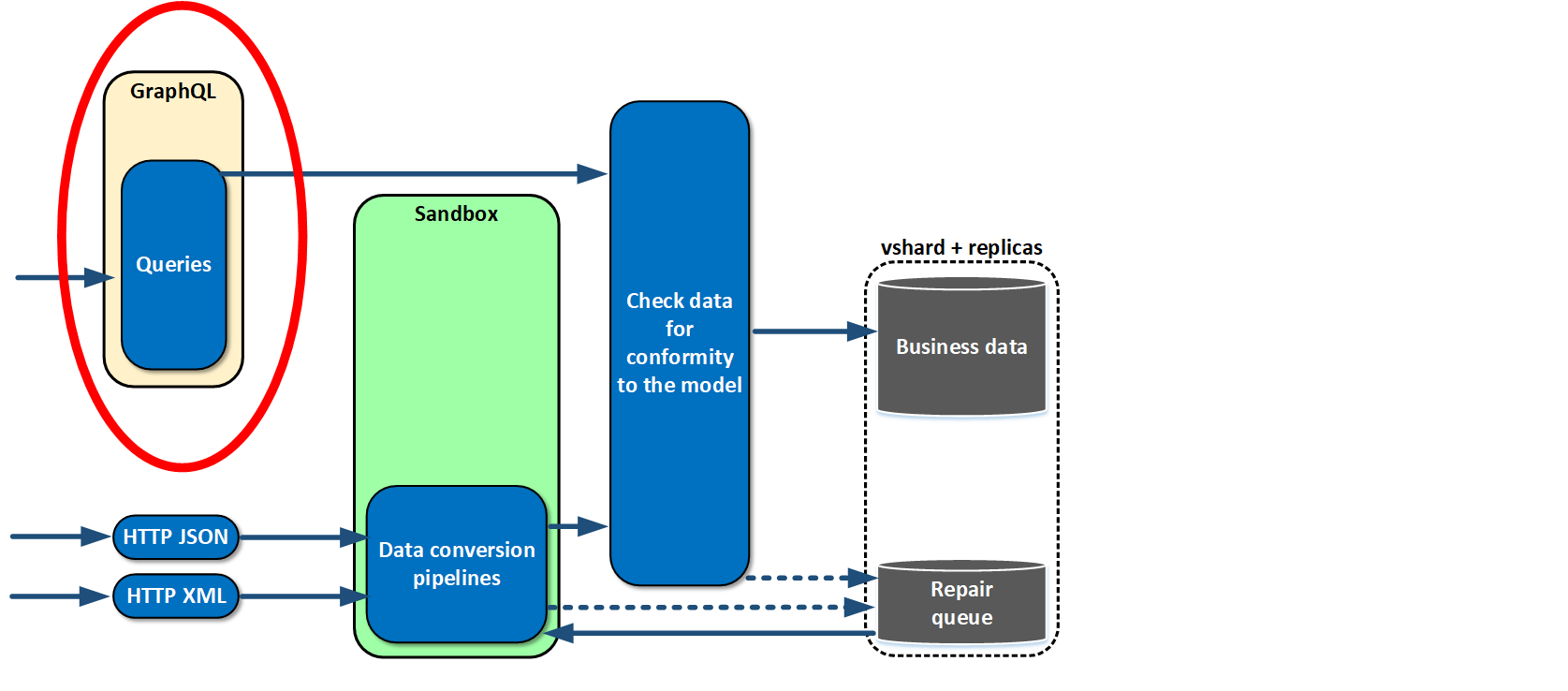
Almost at once, we realized that retrievable data was not enough for us. We made functions which could be linked to objects in a model — essentially, calculated fields. That is, we link to a field some function which calculates mean quotation price, for example. An external user who requests the data doesn’t even know that the field is a calculated field.
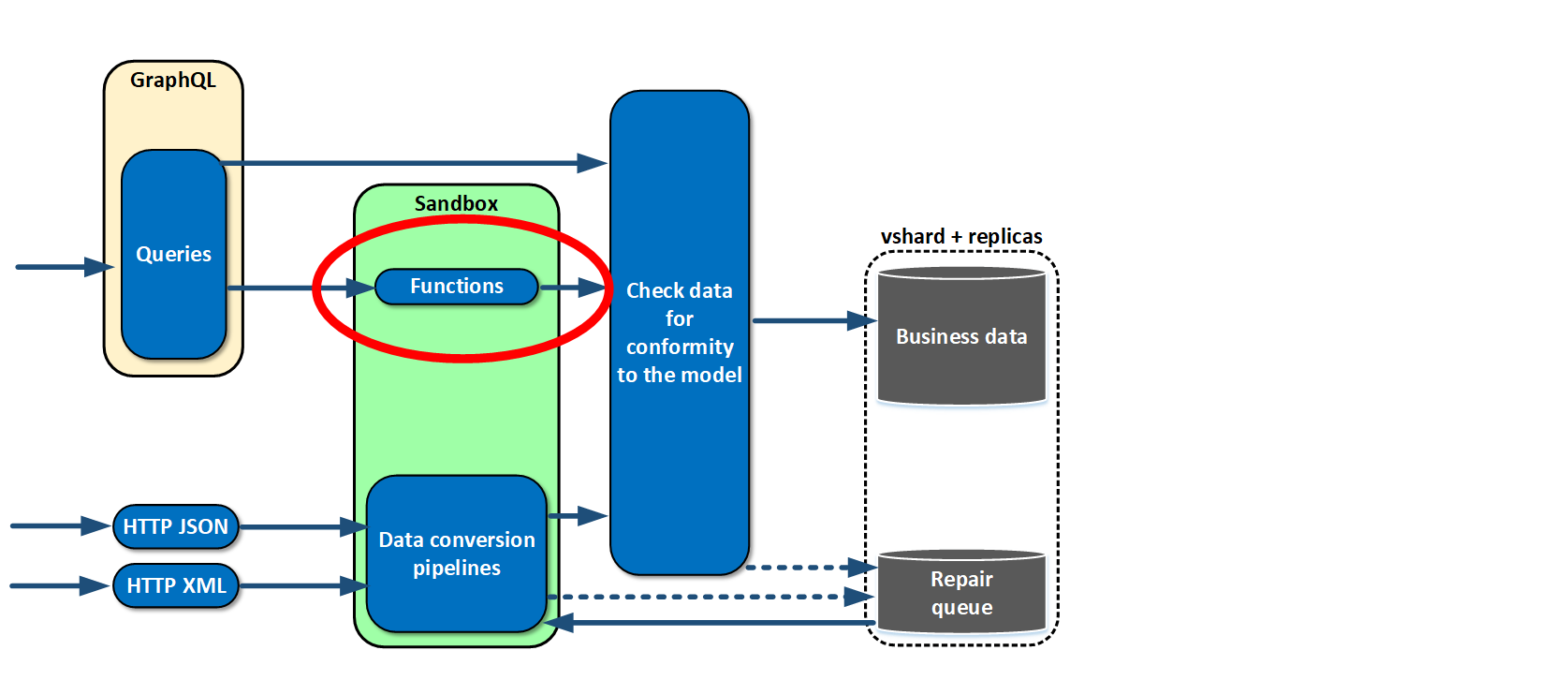
We implemented an authentication system.
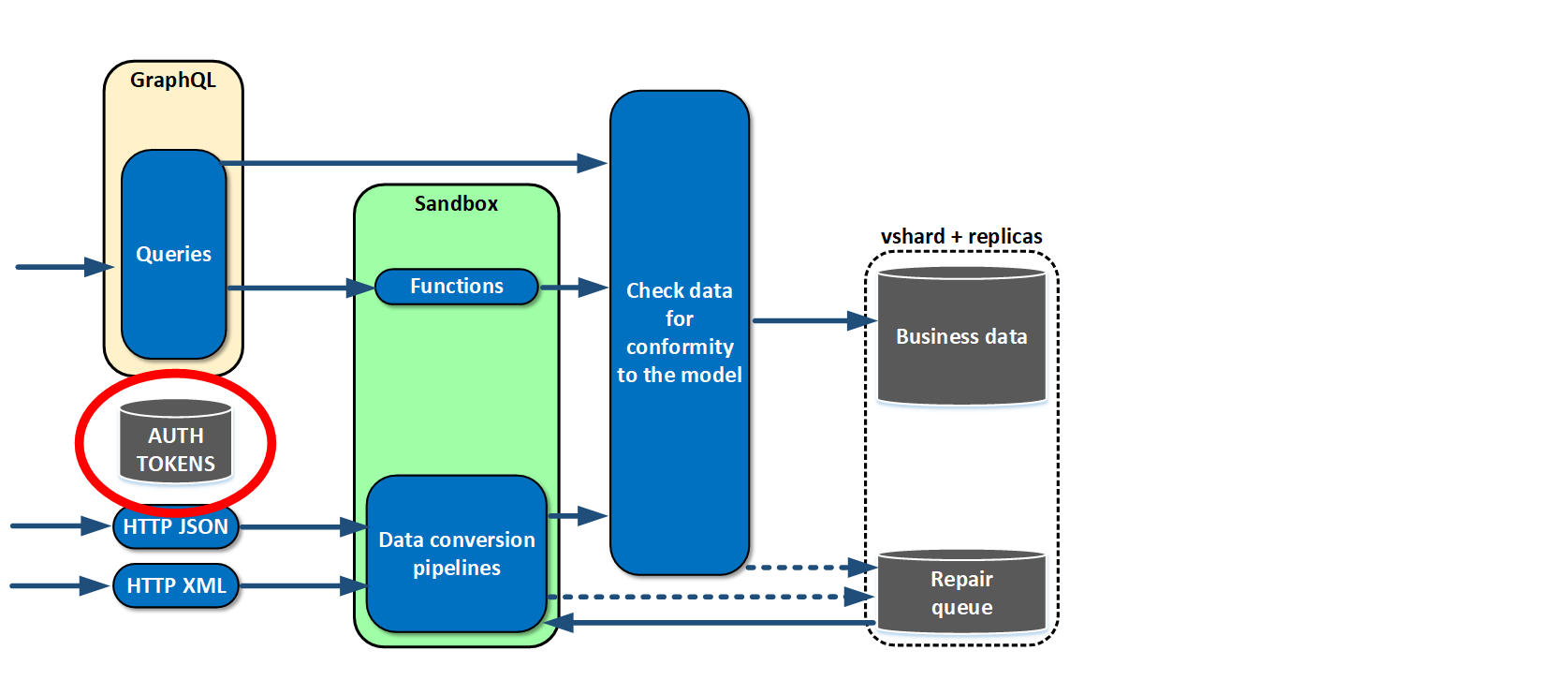
Then we noticed that several roles were crystallizing out in our solution. Role is a kind of an aggregator of functions. Roles normally have different equipment utilization profiles:
- T-Connect: processes inbound connections, limited in CPU usage, consumes less memory, and doesn’t store the status.
- IB-Core: converts data it receives via Tarantool protocol, which means that it manipulates with tables. It doesn’t store status as well, and it can be scaled.
- Storage: only saves data and uses no logic. The most simple interfaces are implemented in this role. It can be scaled through vshard.
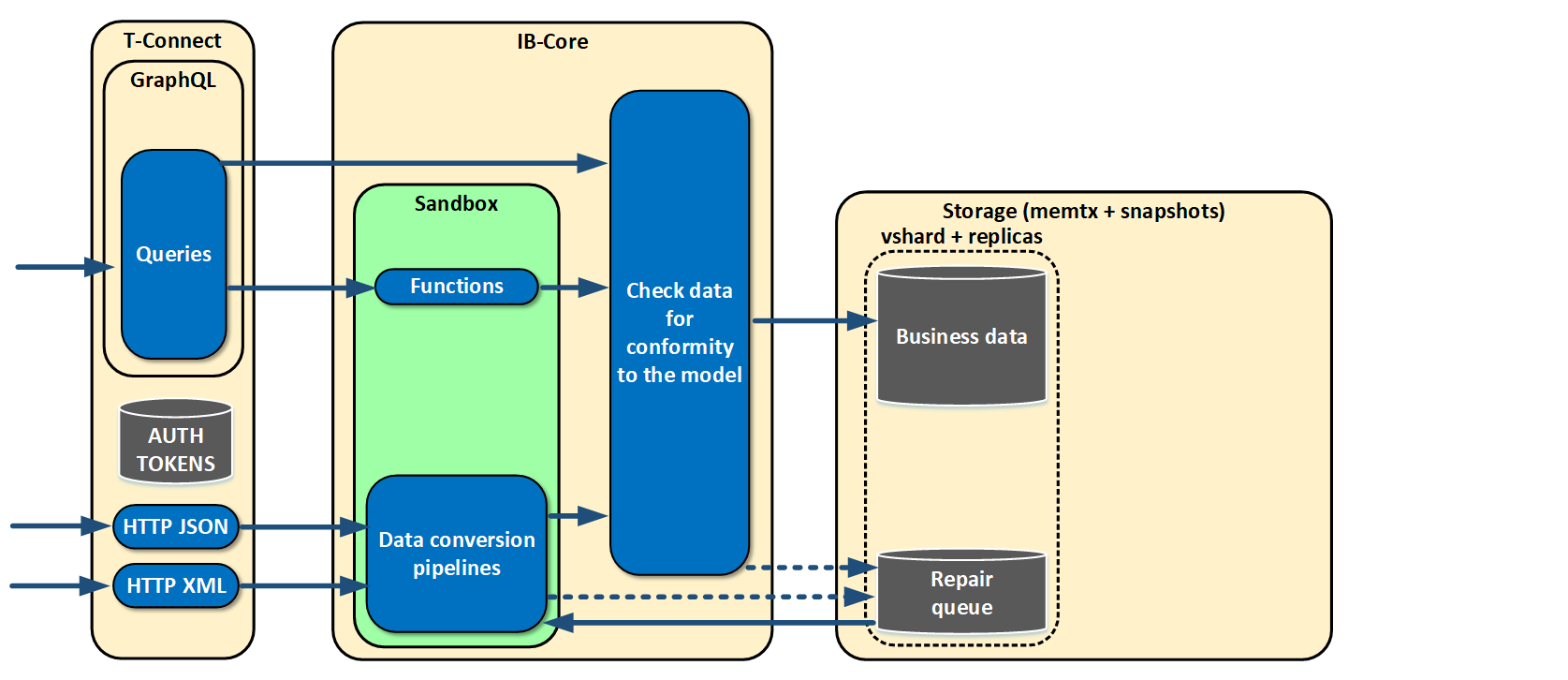
That is, using roles, we unlinked different parts of the cluster from each other, which can be scaled independently.
This way, we created an asynchronous write of transactional data flow and a repair queue with an admin interface. The write is asynchronous from the business perspective: once we have reliably written data in our system, no matter where exactly, we will be able to confirm that. If we don’t confirm, then something went wrong, and the data needs to be resent. This is what writing asynchrony is about.
Testing
At the very start, we decided to instill test-driven development. We write unit tests in Lua using tarantool/tap framework, and integration tests in Python using pytest framework. Doing that, we got both developers and analysts involved in integration test writing.
How do we use test-driven development?
When we want a new feature, we try to write a test for it first. Once a bug is found, we always write a test before fixing it. It is hard to work this way at first, and there are a misunderstanding and even opposition on the part of the staff, like: “Let’s fix it now, then do something new, and then cover it with tests.” However, this almost never happens.
So one needs to will oneself into writing tests in the first place, and make others do the same. Take my word for it, test-driven development pays even in the short term. It will make your life easier. In our perception, about 99% of all code is covered with tests. Quite a lot as it seems, but we have no problem with it: tests are run for every commit.
Yet, we like load testing most. We consider it the most important thing and run such tests on a regular.
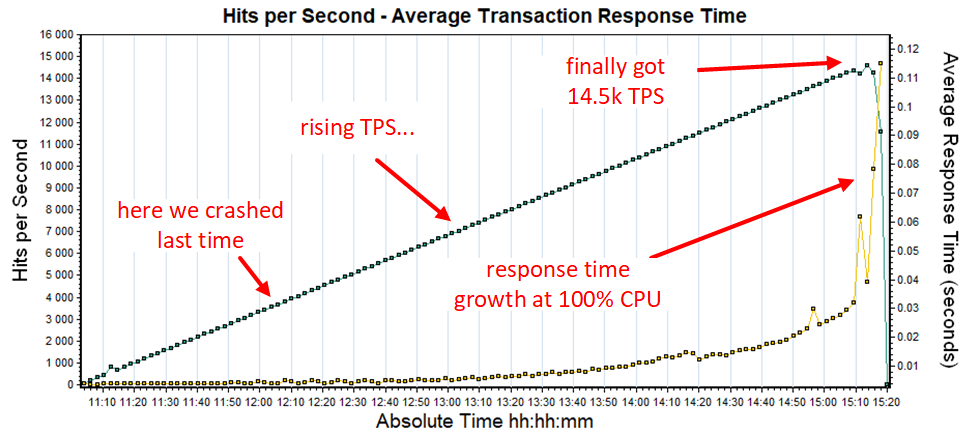
I’m going to tell you a story about how we conducted the first stage of load testing for one of the initial versions. We installed the system on developer’s laptop PC, engaged the load, and got 4 thousand transactions per second. Not bad for a laptop. Then we installed it on a virtual loading test bench comprised of four servers with performance lower than in production. Made a minimum deployment. After launch, we saw that the result was worse than on the laptop in one thread. It was a shock.
Really discouraging. A check of loads on servers showed that they were idle.
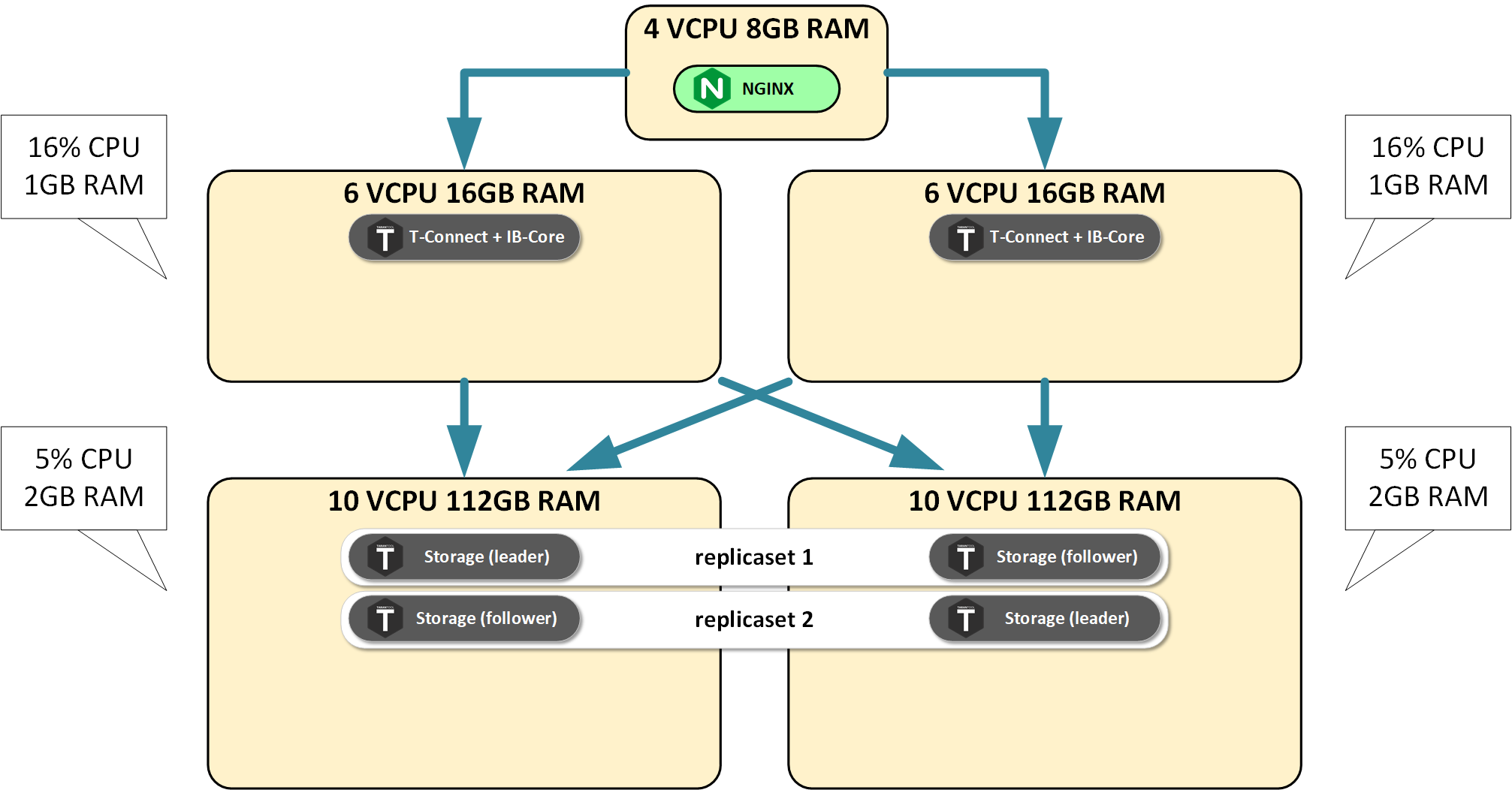
We called the developers, and they told us, people from Java world, that there is only one transaction processor thread in Tarantool. It can be effectively used by only one CPU core under load. With this in mind, we then deployed the maximum possible Tarantool instances on each server, engaged load, and got 14.5 thousand transactions per second.
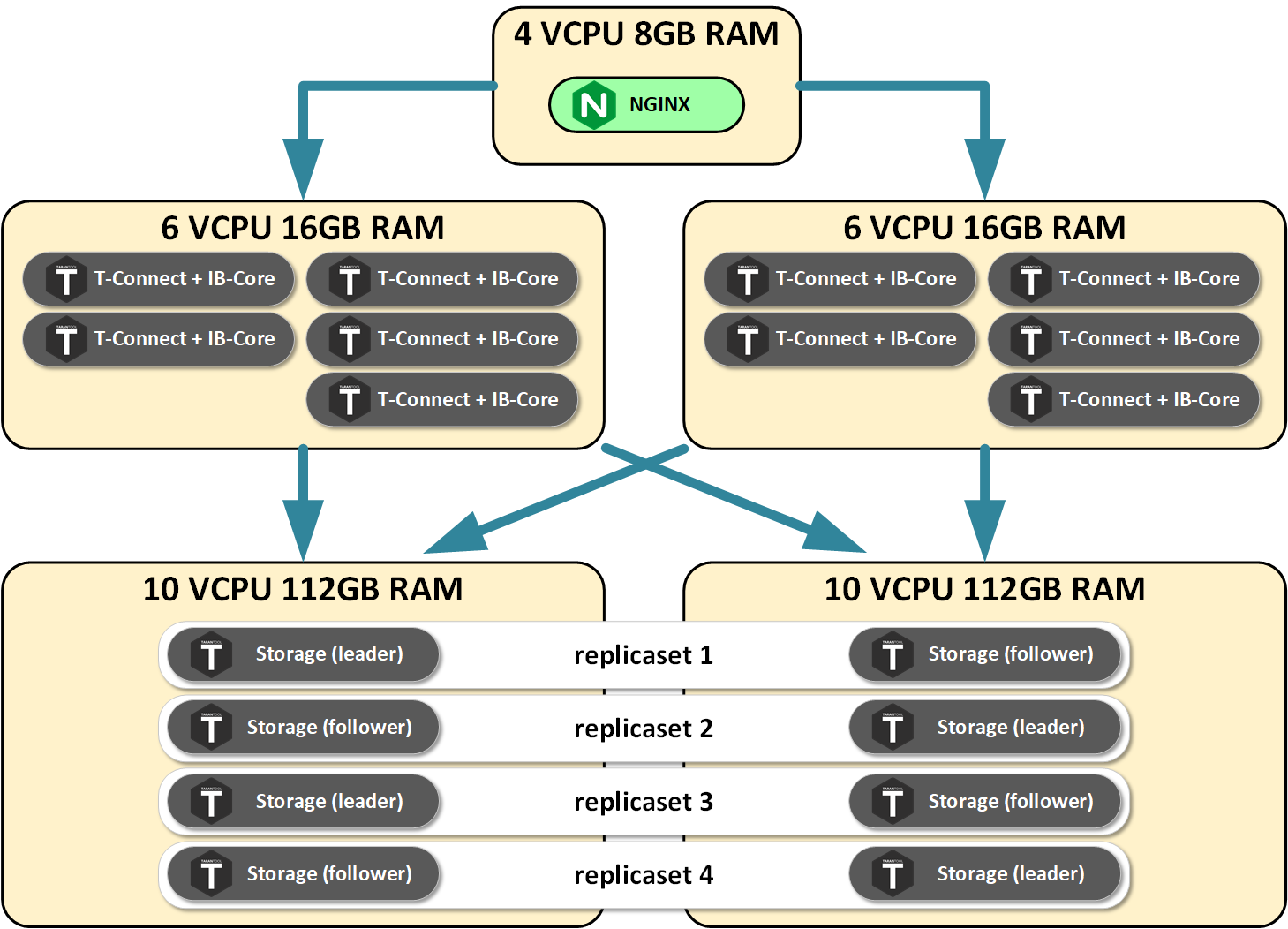
Let me explain one more time. Due to the split-up into roles that use resources differently, our roles responsible for connections processing and data conversion loaded only the CPU, and strictly in proportion to the load.
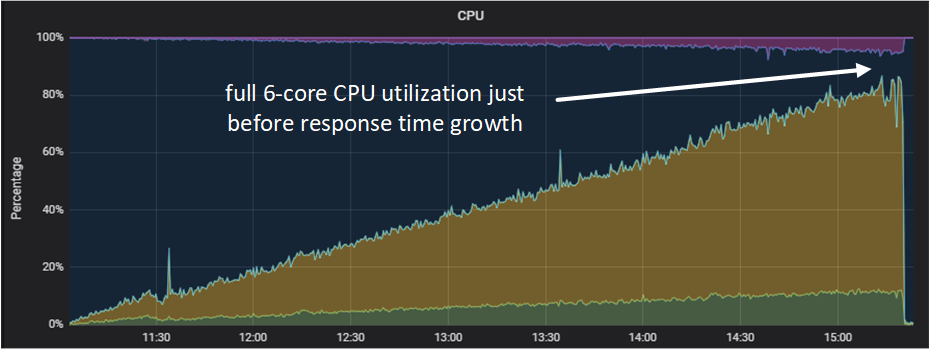
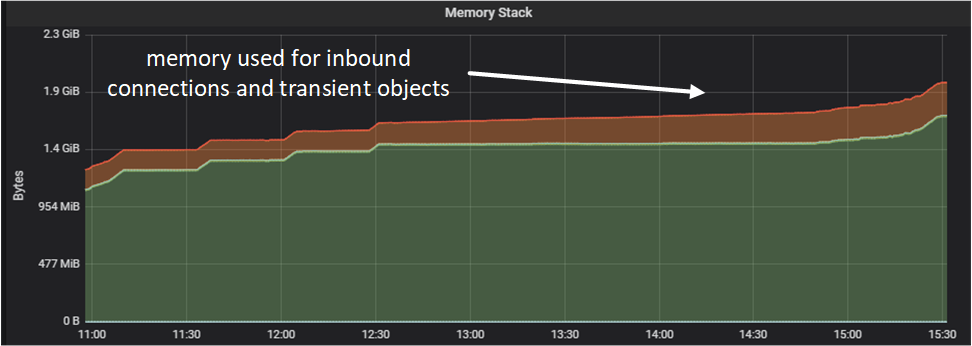
Meanwhile, memory was used only for processing inbound connections and transient objects.
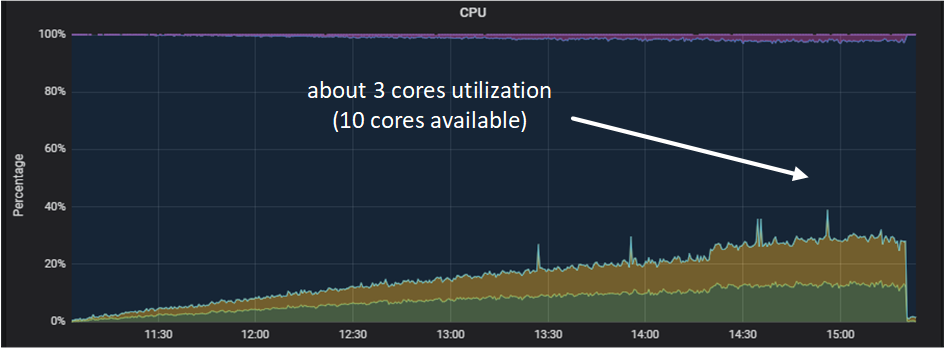
The situation was opposite for storage servers: CPU load was growing, but much slower than for the servers doing connection processing.
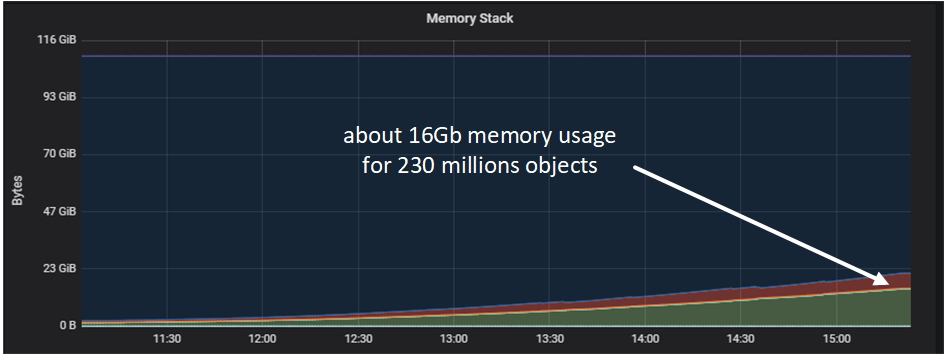
Memory usage was growing in direct proportion to the amount of data being loaded.
Services
To develop our new product exactly as an application platform, we made a component for deploying services and libraries on it.
Services are not just small pieces of code that handle some fields. They can be rather big and complex structures that form a part of a cluster, check reference data, turn over the business logic, and provide responses. The scheme of the service is also exported to GraphQL, and the user gets a one-stop point of access to data, with introspection across the whole model. Quite handy.
Since services include many more functions, we decided that there should be some libraries where we would keep frequently used code. We added those to a safe environment, having verified that nothing is broken as a result. Now we could assign to functions additional environments in the form of libraries.
We wanted to have a platform for both storing data and computing. Since we had a whole lot of replicas and shards, we implemented a semblance of distributed computing and named it “map-reduce”, because it was looking like the original map-reduce.
Legacy systems
Not all of our legacy systems can call us via HTTP and use GraphQL, although they support it. That is why we made a tool enabling data replication to those systems.
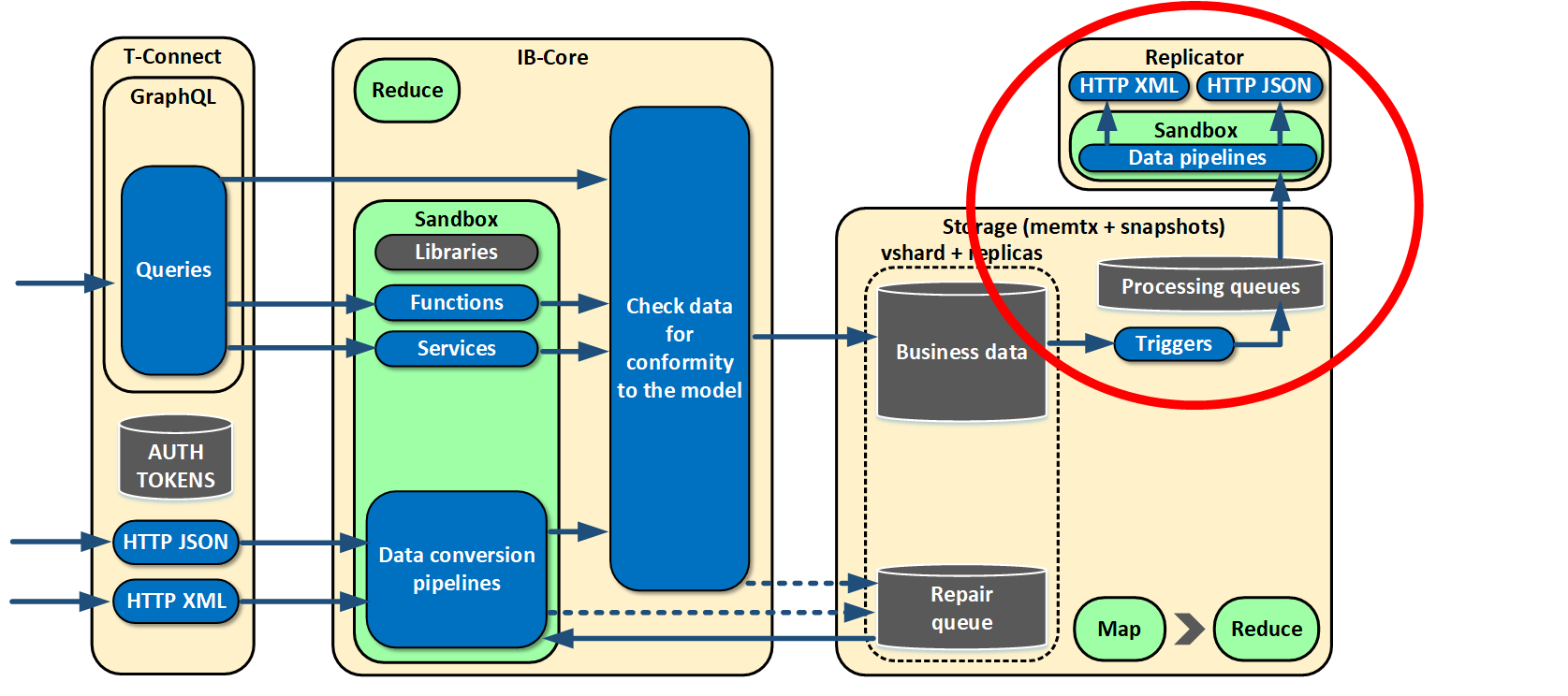
If something changes in our systems, some triggers operate in the Storage role, and a message with the changes gets to the processing queue. The message is sent to an external system via a separate replicator role. This role doesn’t store status.
New modifications
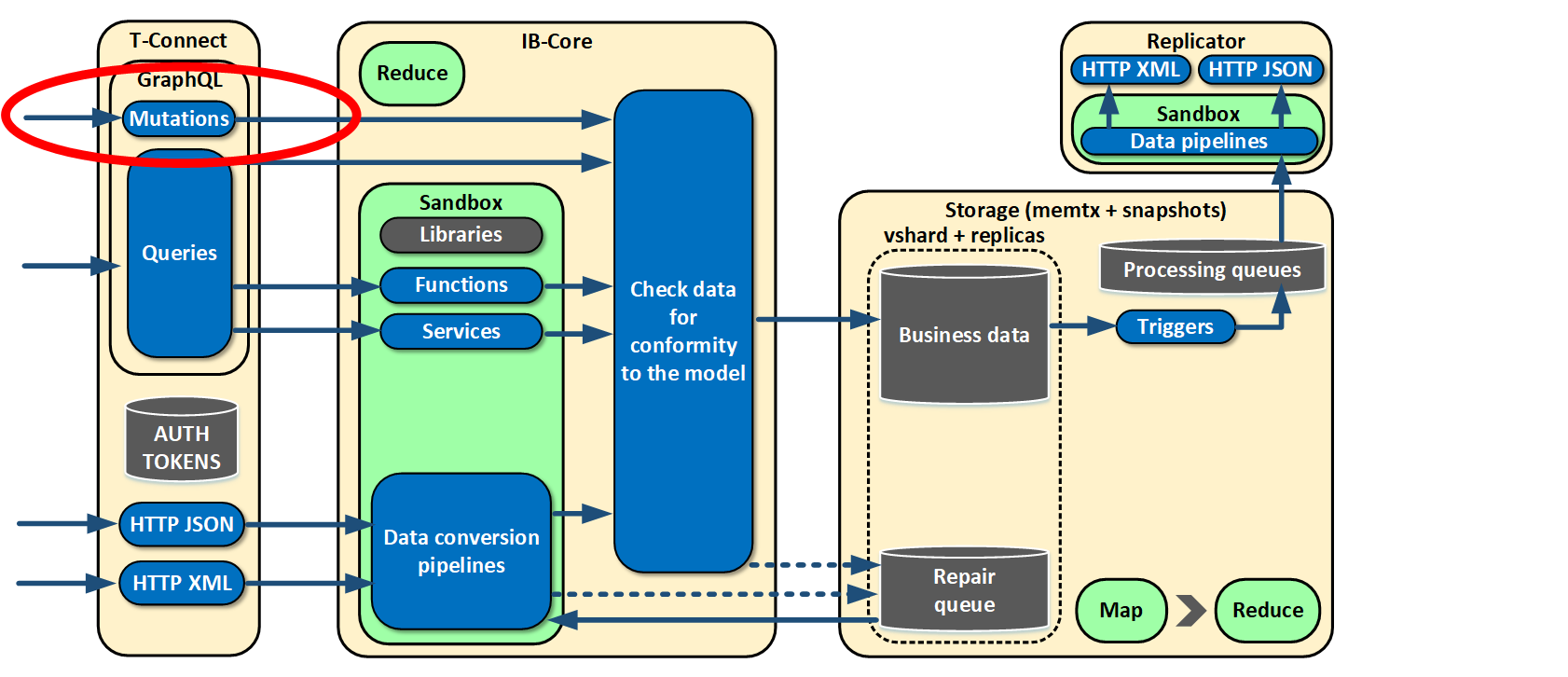
As you remember, we made an asynchronous write from a business perspective. But then we realized that it won’t be enough, because there is a class of systems which need to receive a response with operation status right away. So we extended our GraphQL and added mutations. They fit into the existing data handling paradigm quite naturally. In our systems, it is a single reading and writing point for another class of systems.
We also realized that services alone won’t be enough for us, because there can be rather heavy reports which need to be built daily, weekly, and monthly. It may take longer, and the reports can even block Tarantool’s event loop. That is why we set up separate roles: scheduler and runner. Runners don’t store status. They run heavy tasks that we cannot read on the fly. As to the scheduler role, it supervises the launch schedule for those tasks, which is specified in the configuration. The tasks themselves are stored in the same place as business data. When the time is right, the scheduler takes a task, gives it to a runner, the runner calculates it, and saves the result.
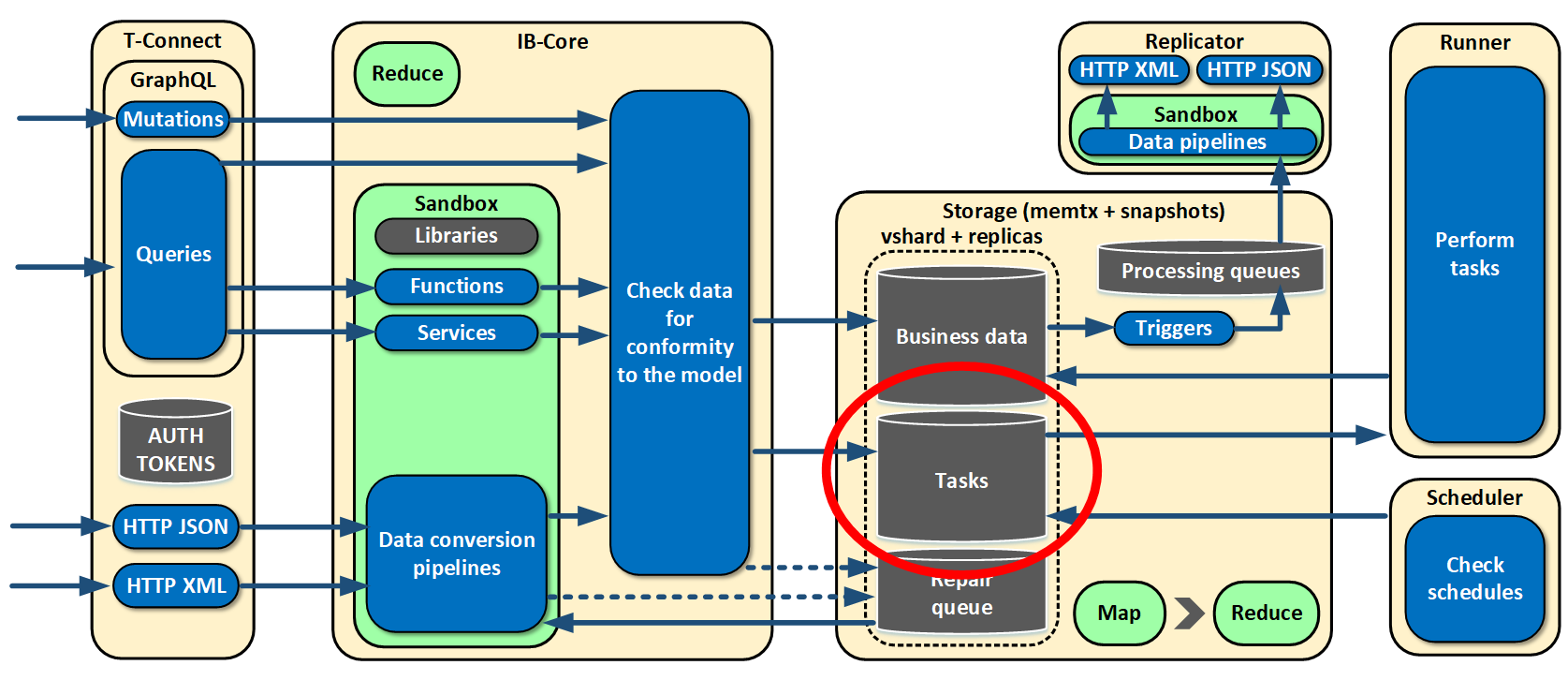
Not all tasks are to be run according to schedule. Some need to be calculated on demand. As soon as such a query comes, a task is generated in the sandbox and sent to a runner for execution. After some time, the user asynchronously receives a response telling that calculation is complete and the report is ready.
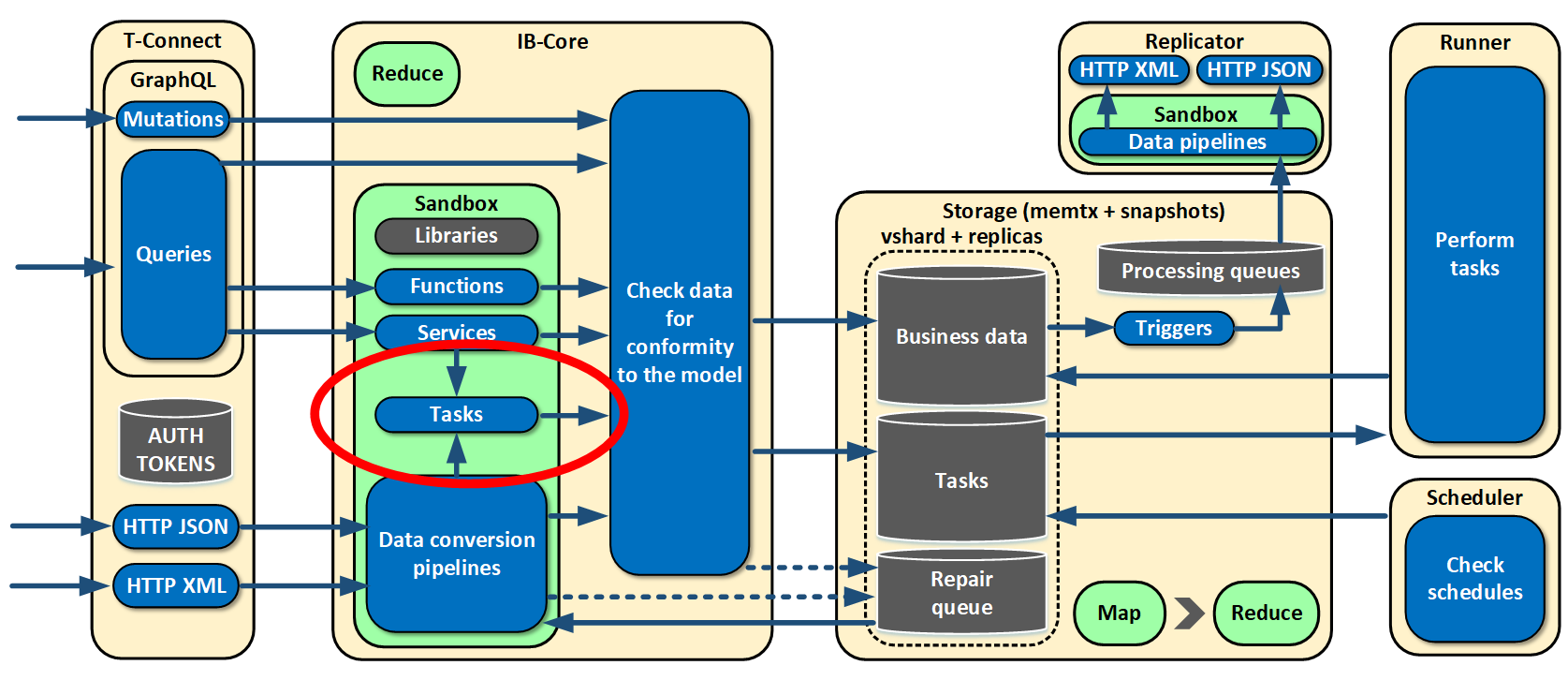
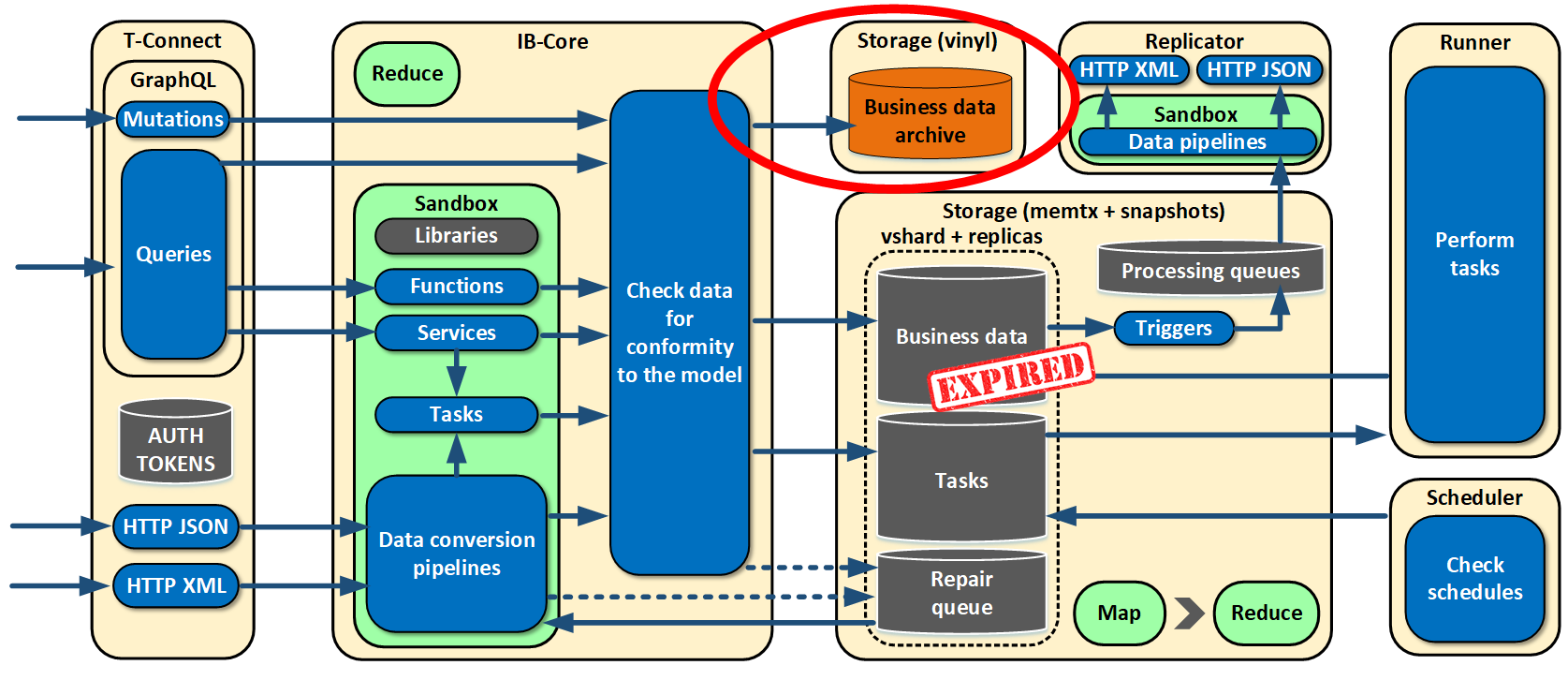
Initially, we adhered to the paradigm of saving all data by versioning and not deleting it. But in real life, we still need to delete something from time to time, such as, basically, some raw data or temporary information. On the basis of expirations, we made a tool for cleaning the storage from obsolete data.
We also realize that, sooner or later, there will be a situation where there is not enough storage space, but the data still needs to be stored. For this purpose, we’re going to make disk storage soon.
Conclusion
We started with the objective of loading data to a single model and spent three months developing it. We had six data supplier systems. The whole code for transformation to a single model is around 30 strings in Lua. The greater part of the work is yet to be done. Sometimes, there’s a lack of motivation in adjacent teams, and there are many circumstances making the work more difficult. If you ever face a similar objective, then the time you think will be enough to achieve it should be multiplied by three, or even four.
Also, remember that existing issues with business processes cannot be resolved using a new data management system, even a high-performance one. What do I mean by this? At the start of our project, we made the customer believe that everything would run like a clockwork once we bring in a new fast database. Processes would run faster, and everything would be OK. In fact, technology cannot resolve all issues that occur in business processes, because business processes are about people. It is people that you should deal with, not technology.
Development through testing at an early stage may be a headache, and it may take very long. But the benefit will be sensible even in the short term when you have to do nothing to conduct regression testing.
It is essential to run load tests at all development stages. The earlier you find a fault in architecture, the easier it will be to correct it, saving you a lot of time in the future.
There is nothing bad in Lua. Everyone can learn to write in it: a Java developer, a JavaScript developer, a Python developer, a front-ender, or a back-ender. We have even analysts writing in it.
When we tell people that we don’t have SQL, it makes them scared. “How do you retrieve data without SQL? Is it possible?” Sure. There’s no need for SQL in an OLTP class system. There is an alternative in the form of a language that returns to you a document-oriented view. GraphQL, for example. Another alternative is distributed computing.
If you realize that you will have to scale up or down, then you should, at the very beginning, design your Tarantool-based solution so that it’s able to operate in parallel with tens of Tarantool instances. If you don’t, you are going to face difficulties and pain at a later stage, because Tarantool can use only one CPU core effectively. ∎

Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.