
Unexpected slow ALTER TABLE in MySQL 5.7
Usually one would expect that ALTER TABLE with ALGORITHM=COPY will be slower than the default ALGORITHM=INPLACE. In this blog post we describe the case when this is not so.
One of the reasons for such behavior is the lesser known limitation of ALTER TABLE (with default ALGORITHM=INPLACE) that avoids REDO operations. As a result, all dirty pages of the altered table/tablespace have to be flushed before the ALTER TABLE completion.
Some history
A long time ago, all “ALTER TABLE” (DDLs) operations in MySQL were implemented by creating a new table with the new structure, then copying the content of the original table to the new table, and finally renaming the table. During this operation the table was locked to prevent data inconsistency.
Then, for InnoDB tables, the new algorithms were introduced, which do not involve the full table copy and some operations do not apply the table level lock – first the online add index algorithm was introduced for InnoDB, then the non-blocking add columns or online DDLs. For the list of all online DDLs in MySQL 5.7 you can refer to this document.
The problem
Online DDLs are great for common operations like add/drop a column, however we have found out that these can be significantly slower. For example, adding a field to a large table on a “beefy” server with 128G of RAM can take unexpectedly long time.
In one of our “small” Percona Servers, it took a little more than 5 min to add a column to the 13 GB InnoDB table. Yet on another “large” Percona Server, where the same table was 30 GB in size, it took more than 4 hours to add the same column.
Investigating the issue
After verifying that the disk I/O throughput is the same on both servers, we investigated the reason for such a large difference in the duration of ALTER TABLE helios ADD COLUMN query using Percona Monitoring and Management (PMM) to record and review performance.
On the smaller server, where ALTER TABLE was faster, the relevant PMM monitoring plots show: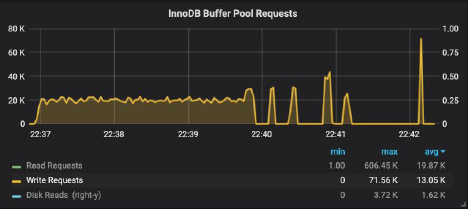
In our Percona Server version 5.7, ALTER TABLE helios ADD COLUMN was executed in place. On the left, we can observe a steady rate of the table rebuild, followed by four spikes corresponding to rebuilding of the four indices.
What is also interesting is that ALTER TABLE with the INPLACE ALGORITHM (which will be the default for adding a field) will need to force flushing of all dirty pages and wait until it is done. This is a much less known fact and very sparsely documented. The reason for this is that undo and redo logging is disabled for this operation:
No undo logging or associated redo logging is required for ALGORITHM=INPLACE. These operations add overhead to DDL statements that use ALGORITHM=COPY. https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-operations.html
In this situation the only option is to flush all dirty pages, otherwise the data can become inconsistent. There’s a special treatment to be seen for ALTER TABLE in Percona Server for MySQL.
Back to our situation – during table rebuild, InnoDB buffer pool becomes increasingly dirty: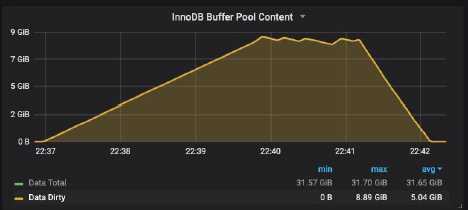
The graph shows peak at about 9 GB corresponding to the table data size. Originally we were under the impression that as dirty pages are flushed to disk, the in-memory dirty pages volume decreases at the rate determined by the Percona adaptive flushing algorithm. It turns out that flushing by ALTER and adaptive flushing have no relation: both happen concurrently. Flushing by ALTER is single page flushing and is done by iterating pages in the flush list and flushing pages of desired space_id (one by one). That probably explains that if the server has more RAM it can be slower to flush as it will have to scan a larger list.
After the last buffer pool I/O request (from the last index build) ends, the algorithm increases the rate of flushing for the remaining dirty pages. The ALTER TABLE finishes when there are no more dirty pages left in the memory.
You can see the six-fold increase in the I/O rate clearly in the plot below: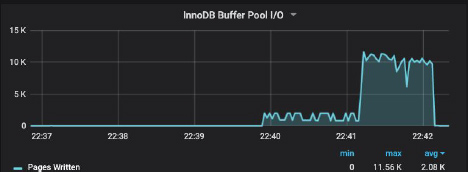
In contrast, on the “large” server, ALTER TABLE behaved differently. Although, at the beginning it proceeded the similar way: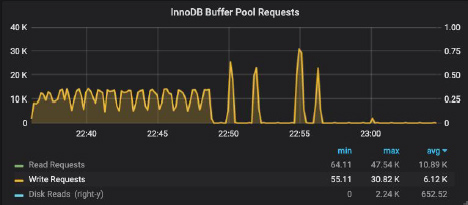
On the left, we can observe a steady rate of the table rebuild, followed by four spikes corresponding to rebuilding of the four table indices. During table rebuild the buffer pool became increasingly dirty: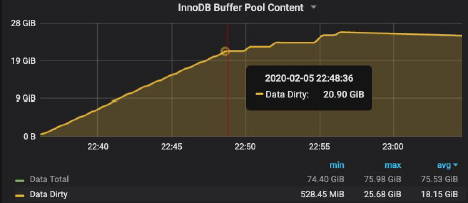
Followed by the 21 GB of the table data, there are four kinks corresponding to four indices builds. It takes about twenty minutes to complete this part of ALTER TABLE processing of the 30 GB table. To some degree this is comparable to about four minutes to complete the similar part of ALTER TABLE processing of the 13 GB table. However, the adaptive flushing algorithm behaved differently on that server. It took more than four hours to complete the dirty pages flushing from memory![]()
This is because in contrast to the “small” server, the buffer pool I/O remained extremely low: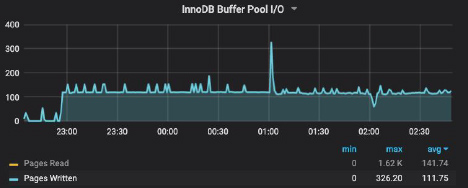
This is not a hardware limitation, as PMM monitoring shows that at other times, the “large” server demonstrated ten times higher buffer pool I/O rates, e.g.: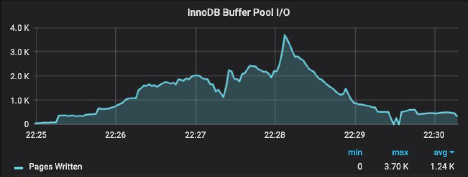
Conclusion
Beware the slower performance of ALTER TABLE … ADD COLUMN (default algorithm is INPLACE). On the large server the difference can be significant: the smaller the buffer pool the smaller is the flush lists and faster the flushing as the ALTER table has a smaller flush_lists to iterate. In some cases it may be better (and with more predictable timing) to use ALTER TABLE ALGORITHM=COPY.
About VirtualHealth
VirtualHealth created HELIOS, the first SaaS solution purpose-built for value-based healthcare. Utilized by some of the most innovative health plans in the country to manage millions of members, HELIOS streamlines person-centered care with intelligent case and disease management workflows, unmatched data integration, broad-spectrum collaboration, patient engagement, and configurable analytics and reporting. Named one of the fastest-growing companies in North America by Deloitte in 2018 and 2019, VirtualHealth empowers healthcare organizations to achieve enhanced outcomes, while maximizing efficiency, improving transparency, and lowering costs. For more information, visit www.virtualhealth.com.
The content in this blog is provided in good faith by members of the open source community. Percona has not edited or tested the technical content. Views expressed are the authors’ own. When using the advice from this or any other online resource test ideas before applying them to your production systems, and always secure a working back up. ∎


Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.