
Are your Database Backups Good Enough?
In the last few years there have been several examples of major service problems affecting businesses data: outages causing data inconsistencies; unavailability or data loss, and worldwide cyberattacks encrypting your files and asking for a ransom.

Database-related incidents are a very common industry issue- even if the root cause is not the database system itself. No matter if your main relational system is MySQL, MariaDB, PostgresQL or AWS Aurora -there will be a time where you will need to make use of backups to recover to a previous state. And when that happens it will be the worst time to realize that your backup system hadn’t been working for months, or testing for the first time a cluster-wide recovery.
Forget about the backups, it is all about recovery!
Let me be 100% clear: the question is not IF data incidents like those can happen to you, but WHEN it will happen and HOW you are prepared to respond to them. It could be a bad application deploy, an external breach, a disgruntled employee, a hardware failure, a provider problem, ransomware infection or a network failure,… Your relational data will eventually get lost, corrupted or in an inconsistent state, and “I have backups” will not be good enough. Recovery plans and tools have to be in place and in a healthy state.
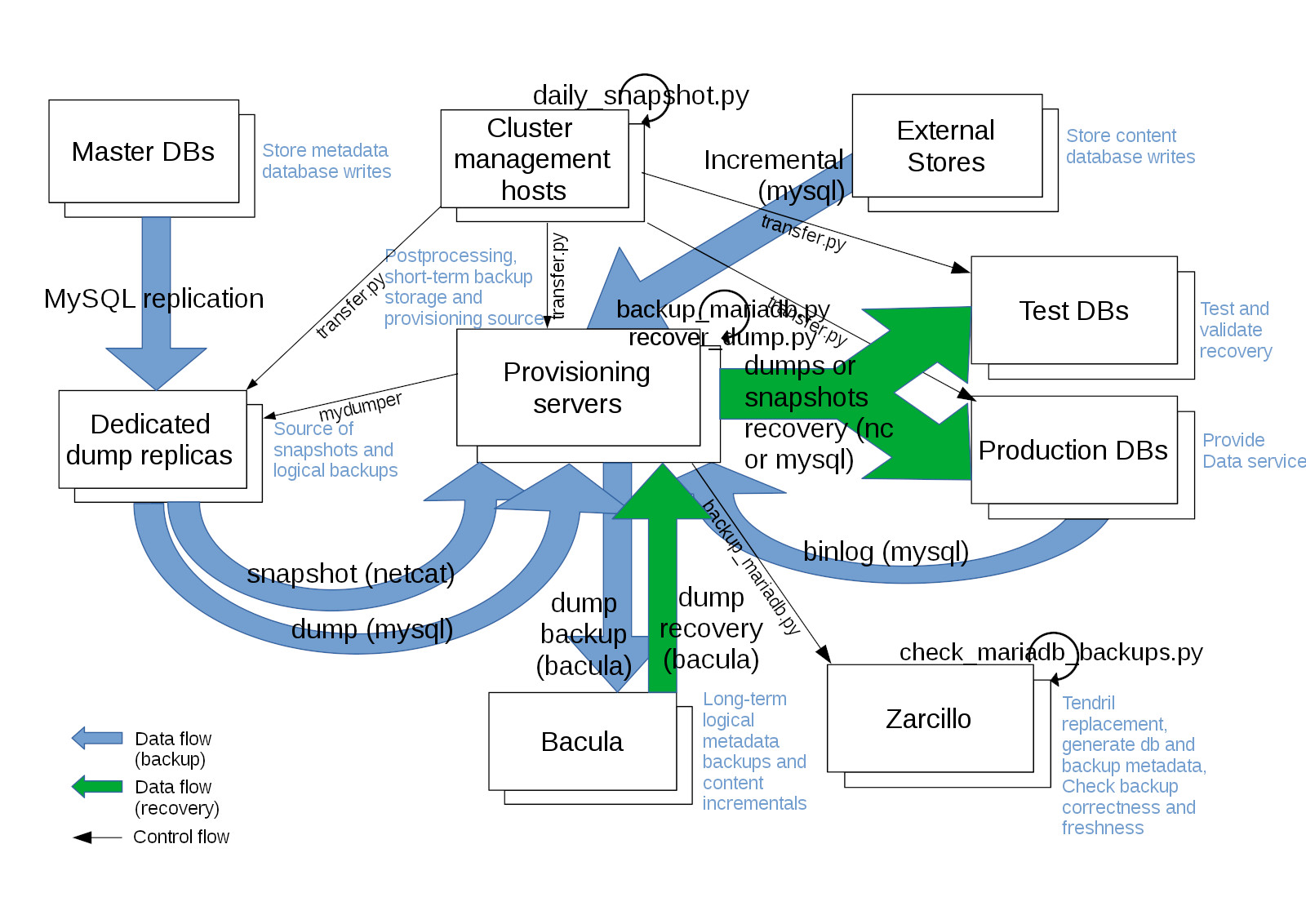
As the only 2 Site Reliability Engineers in charge of the Database Layer of Wikipedia and other projects at the Wikimedia Foundation, Manuel and I grew worried on how to improve both our existing data recovery strategy and provisioning systems. We have the responsibility to make sure that free knowledge contributed by millions of volunteers around the world keeps being available for future generations. As a colleague of us once said- no worries, we “only” are in charge of maintaining the (probably) most valuable collaborative database ever created in the history of mankind! :-D
Among the two of us we handle over half a petabyte of relational data over hundreds of instances and servers, and manual work is off-limits to be efficient. Unlike other popular Internet services, we not only store metadata in MariaDB databases, we also store all content (Wikitext).
- We needed a system that was incredibly flexible - so it worked for both large Wiki databases (like the many terabytes of the English Wikipedia), but also for small but important internal database services such as our bug tracker -.
- fast - able to recover data saturating our 10Gbit network -,
- granular - being able to recover 1 row or an entire instance, to 1 server or an entire cluster; at any arbitrary point in the past-
- and reliable - low rate of failure, but when it failed it should be detected immediately, and not when it is too late.
- The system had to use exclusively free (open source) software and be published itself with a free license.
We ended up with something like this (simplified view :-P):
Our Presentation at Percona Live Europe 2019
A single blog post is not enough to tell the whole story of how we reached the current state – that is why we are going to present the work at the Percona Live Europe 2019 conference which will take place 29 September–2 October in Amsterdam. We will introduce what was the problem we wanted to solve, our design philosophy, existing tooling used and backup methods, backups checking, recovery verification and general automation. You will be able to compare with your own setup and ask questions about why we chose certain paths, based on our experience.
What we have setup may not be perfect, and may not work for you- your needs will be different, as well as your environment. However I expect our presentation will inspire you to design and setup better recovery systems in the future.
See you in Amsterdam! And if you haven’t yet registered, then you are invited to use the code CMESPEAK-JAIME for a 20% discount.
The content in this blog is provided in good faith by members of the open source community. Percona has not edited or tested the technical content. Views expressed are the authors’ own. When using the advice from this or any other online resource test ideas before applying them to your production systems, and always secure a working back up. ∎

Discussion
We invite you to our forum for discussion. You are welcome to use the widget below.